더러운 코드를 작성하는 것은 고통스럽지만, 특히 다른 사람들이 읽을 때는 더욱 힘들죠. 프로그래밍의 가장 어려운 부분은 작동하는 코드를 작성하는 것이 아니라 이해하기 쉽고 의미가 있는 코드를 작성하는 것입니다.
다행히도, 그런 부분에 코드 리뷰가 도움이 됩니다.
이번 주 초에는 함께 작업 중인 프로젝트에 대해 페로우 개발자 (Fabien HIEGEL)로부터 코드 리뷰를 받았고 SLAP 개념을 소개받았습니다.
소프트웨어 설계의 이 원칙은 제 코드를 개선하는 데 도움이 되었고, 오늘은 이를 공유하기 위해 이 개념에 관한 기사를 쓰기로 결정했습니다.
이 게시물에서 SLAP이 무엇인지, 그 이점은 무엇이며 코드에서의 사용 사례를 자세히 살펴보게 될 거에요.
SLAP이란 무엇인가요?
SLAP은 Single Level of Abstraction Principle을 의미합니다. 이는 각 메소드나 함수가 단일 추상화 수준에서 작동해야 한다는 것을 의미합니다. 즉, 한 메소드가 고수준 작업 또는 상세한 저수준 작업 중 하나를 수행해야 하지만 둘 다 혼합해서는 안 된다는 것을 의미합니다.
그런데, 추상화가 정확히 무엇인가요?
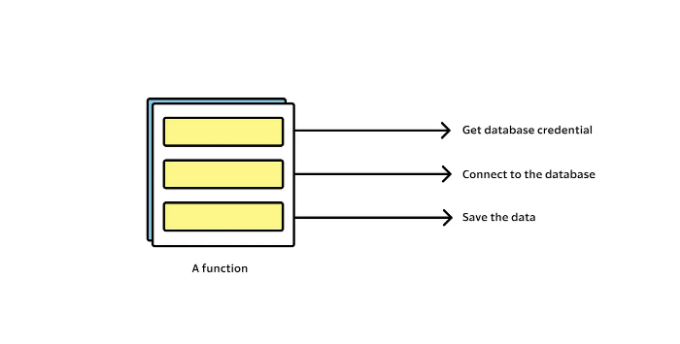
SLAP 원칙 실천하기
파일에서 데이터를 읽고, 데이터를 처리하고, 처리된 데이터를 데이터베이스에 저장하는 시나리오를 고려해 봅시다. SLAP를 따르지 않는 코드 버전부터 시작하여 이 원칙을 준수하도록 코드를 리팩터링하겠습니다.
SLAP 미적용 코드
처음 버전의 코드에서 processData 메서드는 다중 추상화 수준을 처리합니다.
- 파일에서 데이터 읽기 (저수준 작업)
- 데이터 처리 (중간 수준 작업)
- 데이터베이스에 데이터 저장 (고수준 작업)
import java.io.*;
import java.nio.file.*;
import java.sql.*;
public class DataProcessor {
public void processData(String filePath) {
try {
// 저수준 작업: 파일에서 데이터 읽기
String data = new String(Files.readAllBytes(Paths.get(filePath)));
// 중간 수준 작업: 데이터 처리
String processedData = data.toUpperCase(); // 예시 데이터 처리
// 고수준 작업: 데이터베이스에 데이터 저장
saveToDatabase(processedData);
} catch (IOException | SQLException exception) {
exception.printStackTrace();
}
}
private void saveToDatabase(String data) throws SQLException {
// JDBC 연결이 있다고 가정
// 데이터 저장
}
public static void main(String[] args) {
DataProcessor processor = new DataProcessor();
processor.processData("data.txt");
}
}
SLAP을 적용한 리팩토링된 코드
코드를 리팩토링하여 SLAP 원칙을 적용할 수 있습니다. 서로 다른 추상화 수준을 각각의 메소드로 분리하는 방법이 있어요.
import java.io.*;
import java.nio.file.*;
import java.sql.*;
public class DataProcessor {
public void processData(String filePath) {
try {
String data = readFile(filePath); // 고수준 작업
String processedData = process(data); // 고수준 작업
saveToDatabase(processedData); // 고수준 작업
} catch (IOException | SQLException exception) {
exception.printStackTrace();
}
}
private String readFile(String filePath) throws IOException {
// 저수준 작업: 파일에서 데이터 읽기
return new String(Files.readAllBytes(Paths.get(filePath)));
}
private String process(String data) {
// 중간수준 작업: 데이터 처리
return data.toUpperCase(); // 예시 처리
}
private void saveToDatabase(String data) throws SQLException {
// 고수준 작업: 데이터베이스에 데이터 저장
// 데이터 저장
}
public static void main(String[] args) {
DataProcessor processor = new DataProcessor();
processor.processData("data.txt");
}
}
어쩌다보니 조건문 안에서 매우 사소한 조건을 만날 수도 있어요. 아래 코드 예시에서처럼요.
private void saveToDatabase(String data) throws SQLException {
if (Objects.isNull(data)) { // <- 이 조건을 리팩토링할 필요가 없습니다
return
}
// ...
}
Objects.isNull(data)은 saveToDatabase 내에 하이-레벨 코드와 로우-레벨 코드가 섞여 있는 것입니다. SLAP를 적용하는 것이 좋지 않다고 생각하지만, 다른 개발자들이 어떤 조건을 테스트하려는지 이해할 수 있도록 다른 개발자들의 지능에 의존할 수 있습니다.
SLAP의 이점
- 가독성 — 코드를 SLAP에 맞게 작성하면 자명성을 갖게 됩니다. 각 메서드 또는 컴포넌트는 특정 작업에 집중되어 있어 개발자가 그 목적을 이해하기 쉬워집니다.
- 유지보수성 — 관심 분리를 통해 코드를 물리적으로 분리하면 시스템의 관련 없는 부분에 영향을 주지 않고도 특정 코드 조각을 찾고 수정하기가 더 쉬워집니다.
- 테스트 용이성 — 단일 추상화 레벨을 갖는 메서드는 보통 더 쉽게 테스트할 수 있습니다. 왜냐하면 명확하게 정의된 입력과 출력을 갖기 때문입니다.
- 재사용성 — 관심사의 명확한 분리는 시스템의 다른 부분이나 다른 프로젝트에서도 추출하고 재사용할 수 있게 해줍니다.
관련 자료
JavaScript에서 단일 추상화 수준 (SLA) 원칙 코드를 쾅 써요
끝
요약하자면, 단일 추상화 수준 원칙 (SLAP)은 소프트웨어 디자인에서 중요한 개념으로, 코드의 가독성, 유지 보수성, 테스트 가능성 및 재사용성을 촉진합니다.
각 함수 또는 메서드가 하나의 추상화 수준에서 작동하도록 보장함으로써, 개발자들은 더 깨끗하고 효율적인 코드를 작성할 수 있습니다. 이는 이해하고 수정하기 쉬운 코드를 만들어냅니다.
자바나 다른 언어로 코딩 중이더라도 SLAP 원칙을 적용하면 코딩 관행과 소프트웨어 전체의 품질을 크게 향상시킬 수 있습니다.
이 게시물은 원본이 https://www.1kevinson.com에 게시되었습니다.
이 내용이 유익했기를 바라며, 이 튜토리얼이 도움이 되었는지 궁금합니다. 아래 댓글로 의견을 알려주세요.
다가오는 블로그 글을 놓치지 않으려면, 제 뉴스레터를 구독하는 걸 잊지 마세요.
또한 저를 LinkedIn • Twitter • GitHub에서 만나실 수 있습니다. 혹은 제 블로그도 방문해보세요.