아파치 카프카는 링크드인에서 개발된 강력한 오픈소스 스트림 처리 플랫폼이며 아파치 소프트웨어 재단에 기증된 프로젝트입니다. 실시간 데이터 피드를 고 처리량과 낮은 대기 시간으로 처리하기 위해 설계되었습니다. 이 글에서는 카프카가 무엇인지, 사용 사례 및 Java를 사용하여 카프카를 로컬에서 설정하고 실행하는 방법에 대해 상세히 살펴보겠습니다. Spring Boot를 사용하여 프로듀서 및 컨슈머 구성을 수행합니다.
- 카프카란?
- 카프카의 주요 기능
- 카프카의 사용 사례
- 카프카의 추가적인 주요 기능
- 선행 요구사항: 카프카를 위한 Java 설치
- 로컬 장비에 카프카 다운로드 및 설치
- 로컬 장비에서 카프카 실행
- Spring Boot 프로젝트 설정 및 Java 연동
- 샘플 컨트롤러를 사용한 테스트
- 요약
- 결론
카프카란 무엇인가요?
아파치 카프카는 하루에 조 단위 이벤트를 처리할 수 있는 분산 이벤트 스트리밍 플랫폼입니다. 실시간 데이터 파이프라인 및 스트리밍 애플리케이션을 구축하는 데 사용됩니다. 카프카의 아키텍처는 분산 커밋 로그를 기반으로 하며, 데이터는 한 번 쓰여지고 여러 번 읽을 수 있습니다.
카프카의 주요 기능:
- 확장성: 카프카의 분산 아키텍처를 통해 수평 확장이 가능합니다. 즉, Kafka 클러스터에 브로커를 추가하여 시스템의 용량을 늘릴 수 있습니다. 각 브로커는 데이터의 일부를 처리할 수 있어 고 처리량과 부하 분산을 가능하게 합니다.
- 내고장성: 카프카는 데이터 복제를 통해 고 가용성 및 내고장성을 보장합니다. 토픽의 각 파티션은 여러 브로커에 복제되며, 브로커가 실패해도 레플리카를 사용하여 시스템이 계속 작동할 수 있습니다. 이를 통해 데이터 유실을 방지하고 시스템이 작동 가능함을 보장합니다.
- 내구성: 카프카는 데이터를 디스크에 저장하고 여러 브로커에 복제하여 내고장성을 확보합니다. 이를 통해 데이터가 내구성이 있고 장애 발생 시 복구할 수 있습니다. 데이터는 구성 가능한 유지 보수 정책에 따라 보관되어 과거 데이터 분석이 가능합니다.
- 성능: 카프카는 고 처리량과 낮은 지연 시간을 위해 설계되었습니다. 이를 위해 메시지를 배치 처리하고 효율적인 네트워크 프로토콜을 사용하며, 데이터를 매우 최적화된 바이너리 형식으로 저장합니다. 이를 통해 카프카는 대량의 데이터를 실시간으로 처리하는 데 적합합니다.
카프카의 활용 사례
아파치 카프카는 견고한 아키텍처와 고성능 능력으로 많은 조직의 데이터 인프라에서 핵심 구성 요소가 되었습니다. 실시간 대량 데이터 처리 능력을 갖춘 이 카프카는 다양한 응용 프로그램에 적합합니다. 로그 집계부터 스트림 처리 및 이벤트 소싱까지, 카프카의 다재다능함과 신뢰성은 다양한 사용 사례의 요구를 충족할 수 있도록 보장합니다. 본 섹션에서는 카프카가 비즈니스 가치와 운영 효율성을 높이는 데 사용되는 일반적이고 중요한 방법을 탐색합니다.
- 로그 집계: 카프카를 사용하여 다양한 시스템과 응용 프로그램에서 로그를 수집할 수 있습니다. 로그 데이터를 중앙 집중화함으로써 시스템 성능을 분석하고 모니터링하며 이상을 감지하는 것이 더욱 용이해집니다. Elasticsearch 및 Kibana와 같은 도구는 카프카와 통합하여 로그 분석과 시각화에 활용될 수 있습니다.
- 스트림 처리: 카프카는 Kafka Streams를 통해 강력한 스트림 처리 기능을 제공합니다. Apache Storm 및 Apache Flink 등의 스트림 처리 프레임워크도 카프카와 통합하여 실시간 데이터 처리를 할 수 있습니다. 이를 통해 실시간 분석, 모니터링 및 이벤트 기반 응용 프로그램을 구축할 수 있습니다.
- 이벤트 소싱: 이벤트 중심 아키텍처에서 상태 변경은 일련의 이벤트로 캡처됩니다. 카프카는 이벤트 저장소 역할을 하여 모든 이벤트가 안전하게 저장되고 시스템 상태를 재구성하기 위해 다시 재생될 수 있도록 보장합니다. 이는 확장 가능하고 강건한 응용 프로그램을 구축하는 데 유용합니다.
- 데이터 통합: 카프카는 여러 소스에서 데이터를 통합하고 여러 시스템으로 분배하는 중앙 데이터 허브 역할을 합니다. Kafka의 구성 요소 중 하나인 Kafka Connect는 다양한 데이터 소스 및 싱크에 대한 커넥터를 제공하여 데이터베이스, 메시지 큐 및 기타 데이터 시스템과 쉽게 통합할 수 있습니다. 이를 통해 매끄러운 데이터 통합 및 실시간 데이터 파이프라인을 구축할 수 있습니다.
카프카의 추가 주요 기능
아파치 카프카는 대규모, 실시간 데이터 스트리밍을 처리할 수 있는 능력으로 유명합니다. 그 아키텍처는 고 처리량과 낮은 지연 시간을 제공하도록 설계되었지만, 카프카의 능력은 이러한 핵심 속성을 훨씬 뛰어넘습니다. 본 섹션에서는 카프카를 현대적인 데이터 인프라 도구로 만드는 데 반드시 필수적인 추가 주요 기능을 다룹니다. 확장성, 내결함성, 내구성, 성능을 비롯한 카프카 종합 기능 세트는 견고하고 효율적이며 신뢰할 수 있는 데이터 스트리밍 및 처리를 보장합니다. 이러한 기능을 이해하는 것은 다양한 데이터 주도형 응용 프로그램에서 카프카를 최대한 활용하는 데 중요합니다.
- 높은 처리량: Kafka는 효율적으로 메시지를 배치하고 네트워크 통신에 제로 복사 기술을 사용하며 기본 파일 시스템의 고성능을 활용하여 높은 처리량을 처리할 수 있습니다.
- 낮은 지연 시간: Kafka는 낮은 지연 시간의 메시지 전달을 위해 설계되었습니다. 시스템은 메시지가 최소한의 지연으로 전달되도록 보장하여 실시간 애플리케이션에 적합합니다.
- 다중 테넌시: Kafka는 다중 테넌시를 지원하여 여러 사용자나 애플리케이션이 동일한 Kafka 클러스터를 공유하면서 격리 및 보안을 유지할 수 있습니다.
- 백프레셔 처리: Kafka는 속도 제한 및 흐름 제어 메커니즘을 적용하여 백프레셔를 처리할 수 있습니다. 이를 통해 느린 소비자가 시스템을 압도하고 성능 저하를 초래하지 않도록 합니다.
- 유연한 데이터 보존: Kafka는 유연한 데이터 보존 정책을 제공하여 사용자가 데이터를 보존하는 기간을 구성할 수 있습니다. 데이터는 특정 기간 동안 보존되거나 특정 크기 제한에 도달할 때까지 보존할 수 있습니다.
이러한 기능을 활용하여 Kafka는 확장 가능하고 신뢰할 수 있으며 고성능 데이터 스트리밍 및 이벤트 기반 애플리케이션을 구축하는 강력한 플랫폼이 됩니다.
준비물: Kafka를 위한 Java 설치
Apache Kafka를 설정하기 전에 Kafka가 Java 가상 머신(JVM)에서 실행되므로 컴퓨터에 Java가 설치되어 있어야 합니다. 이 안내서는 로컬 컴퓨터에 Java를 설치하는 과정을 안내할 것입니다.
자바 설치 단계별 안내서
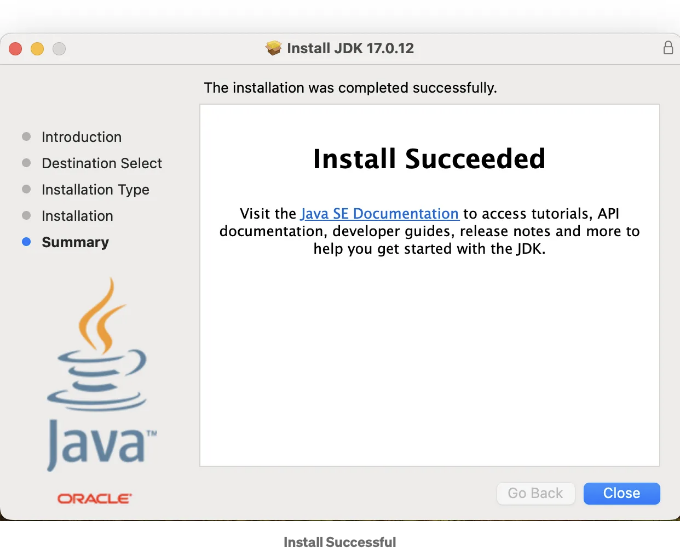
단계 1: 자바 개발 키트(JDK) 다운로드
- Oracle JDK 다운로드 페이지로 이동: Oracle JDK 다운로드 페이지를 방문합니다.
- JDK 버전 선택: 운영 체제에 맞는 적절한 JDK 버전을 선택합니다 (예: Windows, macOS, Linux).
- 설치 프로그램 다운로드: 운영 체제에 맞는 다운로드 링크를 클릭하여 JDK 설치 프로그램을 다운로드합니다.
단계 2: Windows에 JDK 설치하기
- 설치 프로그램 실행: 다운로드한 JDK 설치 파일을 찾아 (예: jdk-
version-windows-x64.exe) 더블 클릭하여 실행합니다. - 설치 마법사 따르기: 설치 마법사의 지시에 따라 진행합니다. 라이선스 동의를 받아들이고 설치 디렉토리를 선택합니다(기본값으로 지정하셔도 됩니다).
- 설치 완료: 설치 단계를 진행하기 위해 "다음"을 클릭합니다. 최종으로 "완료"를 클릭하여 설치를 완료합니다.
단계 3: macOS에 JDK 설치하기
- 설치 프로그램 실행: 다운로드한 JDK .dmg 파일을 찾아 더블 클릭하여 엽니다.
- 설치 마법사 따르기: JDK 패키지 아이콘을 더블 클릭하여 설치 프로그램을 실행합니다. 지시에 따라 진행하고 설치를 진행하려면 "계속"을 클릭합니다.
- 설치 완료: 설치 프로세스를 시작하려면 "설치"를 클릭합니다. 요청시 macOS 관리자 암호를 입력합니다. 설치를 완료하려면 "닫기"를 클릭합니다.
단계 4: 리눅스에 JDK 설치하기
- 터미널 열기: 리눅스 시스템에서 터미널 창을 엽니다.
- 패키지 저장소 업데이트: 다음 명령을 사용하여 패키지 저장소를 업데이트합니다:
sudo apt update
- JDK 설치: 다음 명령을 사용하여 기본 JDK 패키지를 설치합니다:
sudo apt install default-jdk
- 설치 확인: Java 버전을 확인하여 JDK 설치를 확인합니다.
java -version
- JAVA_HOME 환경 변수 설정하기.
-
JDK 설치 경로 찾기: JDK의 설치 경로를 찾아보세요. 기본 설치 경로는 다음과 같습니다:
- Windows: C:\Program Files\Java\jdk-
버전 - macOS: /Library/Java/JavaVirtualMachines/jdk-
버전.jdk/Contents/Home - Linux: /usr/lib/jvm/java-
버전-openjdk-amd64
- Windows: C:\Program Files\Java\jdk-
-
Windows에서 JAVA_HOME 설정하기:
- 시작 메뉴를 열고 "환경 변수"를 검색합니다.
- "시스템 환경 변수 편집"을 클릭합니다.
- 시스템 속성 창에서 "환경 변수" 버튼을 클릭합니다.
- "시스템 변수" 아래에서 "새로 만들기"를 클릭하여 새 변수를 생성합니다.
- 변수 이름을 JAVA_HOME으로 설정하고 변수 값은 JDK 설치 경로로 지정합니다.
- 변경 사항을 저장하려면 "확인"을 클릭합니다.
-
macOS 및 Linux에서 JAVA_HOME 설정하기:
-
터미널 창을 엽니다.
-
텍스트 편집기를 사용하여 셸 프로필 파일(~/.bashrc, ~/.zshrc 또는 ~/.profile)을 편집합니다:
nano ~/.bashrc
// 다음 줄을 추가하여 JAVA_HOME 변수 설정:
export JAVA_HOME=<JDK_INSTALL_PATH>
export PATH=$JAVA_HOME/bin:$PATH
// 변경 사항 적용
source ~/.bashrc
단계 6: JAVA_HOME 변수 확인
- 터미널이나 명령 프롬프트를 엽니다: 터미널 창(Linux/macOS)이나 명령 프롬프트(Windows)를 엽니다.
- JAVA_HOME 확인: JAVA_HOME 변수가 올바르게 설정되어 있는지 확인합니다:
echo $JAVA_HOME
- 출력 결과에는 JDK 설치 경로가 표시되어야 합니다.

자바가 설치되어 컴퓨터에 구성되어 있으면 이제 Kafka 설치와 설정을 진행할 준비가 된 것입니다.
로컬 머신에 Kafka 다운로드 및 설치
로컬 컴퓨터에 Kafka를 설정하는 것은 이 강력한 이벤트 스트리밍 플랫폼의 잠재력을 활용하는 첫 번째 단계입니다. 로컬에서 애플리케이션을 빌드하고 테스트하려는 개발자이거나 Kafka의 기능을 탐험하고 싶어하는 열정가 있는 분이라면, 로컬 Kafka 환경을 갖는 것은 매우 중요합니다. 이 섹션에서는 로컬 컴퓨터에 Kafka를 다운로드하고 설치하는 과정을 안내합니다. 필수 조건, 설치 단계, Kafka를 구성하는 방법을 다룰 것입니다. 이 안내서를 따르면 로컬 설정에 완전히 작동하는 Kafka 인스턴스가 준비되어 개발 및 실험에 사용할 준비가 됩니다.
단계 1: Kafka 다운로드
- 아파치 카프카 다운로드 페이지로 이동합니다.
- Kafka의 최신 버전을 다운로드하세요 (예: Kafka-3.7.1-src.tgz).
저희는 현재 Kafka-3.7.1-src.tgz 버전을 사용하고 있습니다. Docker 이미지도 가져올 수 있습니다.

단계 2: Kafka 압축 해제
원하는 디렉토리에 다운로드한 파일을 압축 해제하세요:
tar -xzf Kafka-3.7.1-src.tgz
cd Kafka-3.7.1-src
로컬 머신에서 Kafka 실행하기
단계 1: ZooKeeper 시작하기
카프카는 분산 브로커를 관리하기 위해 주키퍼를 필요로 합니다. 아래 명령어를 실행하여 주키퍼를 시작하세요:
bin/zookeeper-server-start.sh config/zookeeper.properties

단계 2: 카프카 브로커 시작
다른 터미널을 열어 Kafka 브로커를 시작해주세요:
bin/kafka-server-start.sh config/server.properties

Java로 Spring Boot 프로젝트 설정하기
Spring Boot은 빠르고 효율적으로 Java 애플리케이션을 빌드하기 위한 강력하고 유연한 프레임워크입니다. 개발자들이 애플리케이션을 구성하는 대신 비즈니스 로직 작성에 집중할 수 있도록 포괄적인 인프라를 제공하여 개발 프로세스를 간소화합니다. 이 섹션에서는 Java로 Spring Boot 프로젝트를 설정하는 단계를 안내해 드립니다. 필요한 선행 조건, 새 Spring Boot 프로젝트 생성 방법 및 견고하고 확장 가능한 애플리케이션 작성에 시작하기 위한 구성 방법을 다룰 것입니다. 이 섹션을 마치면 개발 및 배포 준비가 완료된 완전히 기능하는 Spring Boot 프로젝트를 보유하게 될 것입니다.
단계 1: Spring Boot 프로젝트 생성
다음 종속성을 사용하여 Spring Initializr를 사용하여 새 Spring Boot 프로젝트를 생성하십시오:
- Spring Web
- Spring for Apache Kafka
- Lombok
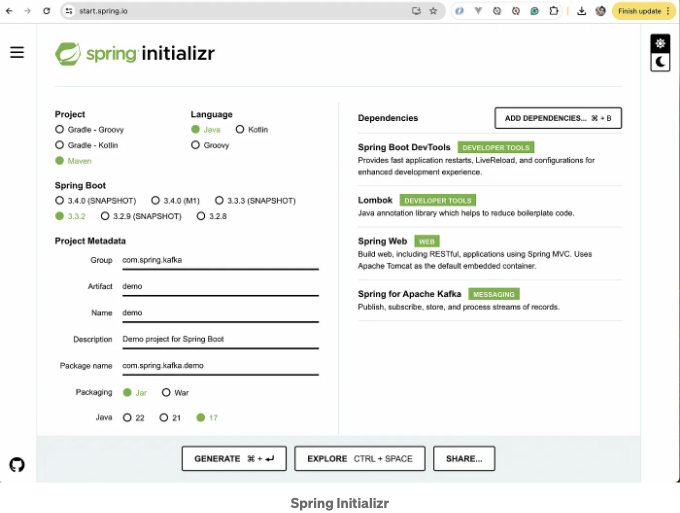
IntelliJ IDEA에 Spring Boot 프로젝트를 가져오고 프로젝트를 시작하면 위의 이미지와 비슷한 화면이 나타납니다. 화면의 왼쪽에 프로젝트 구조가 표시되며, src, target과 같은 디렉토리, .gitignore 및 HELP.md와 같은 구성 파일이 표시됩니다.
DemoApplication.java 파일은 src/main/java/com/spring/kafka/demo 아래에 있습니다. 이것은 Spring Boot 애플리케이션의 주진입점이며 @SpringBootApplication 어노테이션으로 표시됩니다. 이 어노테이션은 다음과 같은 모든 것을 추가하는 편의를 제공합니다:
- @Configuration: 응용 프로그램 컨텍스트의 빈 정의 소스로 표시하는 어노테이션입니다.
- @EnableAutoConfiguration: 클래스패스 설정, 다른 빈 및 다양한 속성 설정에 따라 빈 추가를 시작하도록 Spring Boot에 지시합니다.
- @ComponentScan: com/spring/kafka/demo 패키지에서 다른 구성 요소, 구성 및 서비스를 찾아 컨트롤러를 찾을 수 있도록 Spring에 지시합니다.
애플리케이션을 실행하면 IntelliJ IDEA가 화면 하단의 콘솔에 출력을 표시합니다. 로그에는 Spring Boot 애플리케이션이 성공적으로 시작되었음을 나타내며 포트 8080에서 내장 Tomcat 서버를 초기화했습니다. 로그는 다양한 빈의 로딩과 웹 애플리케이션 컨텍스트의 초기화를 포함한 시작 프로세스에 대한 자세한 정보를 제공합니다.
여기는 pom.xml 파일 내용입니다.
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.3.2</version>
<relativePath/> <!-- repository에서 부모 찾기 -->
</parent>
<groupId>com.spring.kafka</groupId>
<artifactId>demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>demo</name>
<description>Spring Boot용 데모 프로젝트</description>
<url/>
<licenses>
<license/>
</licenses>
<developers>
<developer/>
</developers>
<scm>
<connection/>
<developerConnection/>
<tag/>
<url/>
</scm>
<properties>
<java.version>17</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>
Producer Configuration and Setup
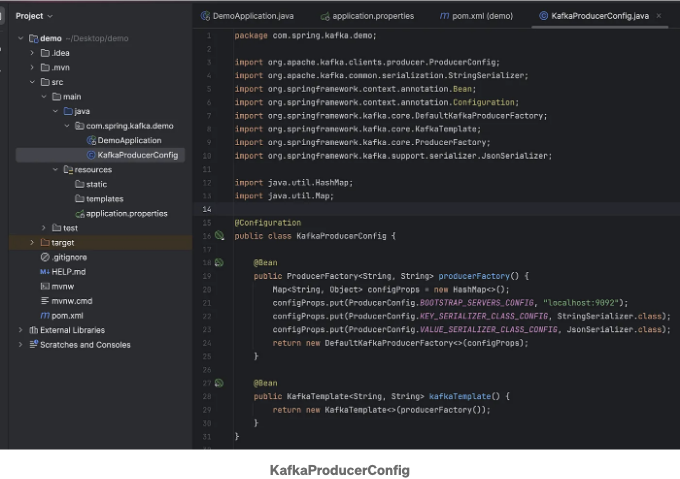
카프카 프로듀서를 위한 구성 클래스를 만들어보세요: KafkaProducerConfig 클래스는 Kafka 프로듀서를 설정하는 데 사용되는 Spring Boot 구성 클래스입니다. 자세한 설명은 다음과 같습니다:
구성 클래스
- 해당 클래스는 @Configuration 주석으로 표시되어 있습니다. 이는 스프링 애플리케이션 컨텍스트에 대한 빈을 정의한다는 것을 의미합니다.
Producer Factory
- producerFactory 메서드는 @Bean으로 주석 처리되어 있어 Spring 컨테이너에서 관리될 것을 의미합니다.
- 이 메서드는 Kafka Producer 인스턴스를 생성하는 ProducerFactory
String, String를 생성합니다. - 구성 속성:
- ProducerConfig.BOOTSTRAP_SERVERS_CONFIG: Kafka 브로커 주소를 지정합니다 (이 경우 localhost:9092).
- ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG: 키에 대한 직렬화 비클래스를 정의합니다 (StringSerializer 사용).
- ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG: 값에 대한 직렬화 클래스를 정의합니다 (JsonSerializer 사용).
Kafka Template
- kafkaTemplate 메서드도 @Bean으로 주석 처리되어 있습니다.
- 이 메서드는 Kafka 토픽으로 메시지를 전송하기 위한 고수준 API인 KafkaTemplate
String, String을 생성합니다. - producerFactory 빈을 사용하여 템플릿을 생성하며, 프로듀서 설정이 적용됩니다.
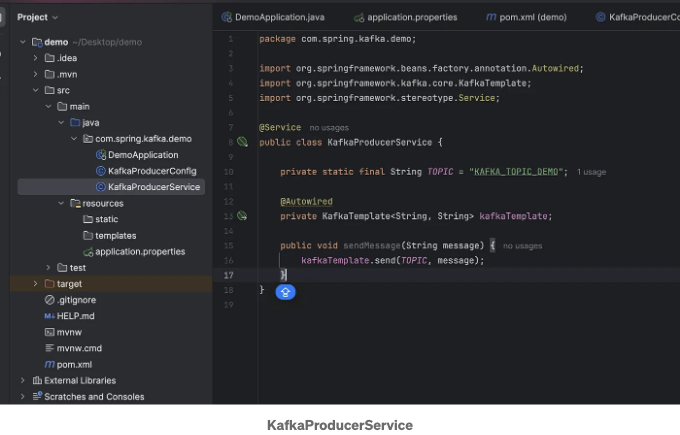
메시지를 전송하는 서비스 클래스를 생성하세요. Spring Boot의 KafkaProducerService 클래스는 지정된 Kafka 토픽으로 메시지를 전송하기 위해 설계되었습니다. 이 클래스는 @Service로 주석이 달려 있어 Spring 서비스 구성요소로 지정됩니다. "KAFKA_TOPIC_DEMO"로 Kafka 토픽 이름을 지정하는 상수 TOPIC을 정의합니다.
이 클래스는 Spring에 의해 자동으로 주입되는 KafkaTemplate을 사용합니다. KafkaTemplate은 데이터를 보내는 데 필요한 고수준 메서드를 제공하여 Kafka와 상호 작용하는 것을 간단화합니다.
이 서비스의 sendMessage 메서드는 주어진 메시지를 미리 정의된 Kafka 토픽으로 전송합니다. String 형식의 메시지를 매개변수로 받아들이고 KafkaTemplate의 send 메서드를 사용하여 메시지를 토픽에 발행합니다. Spring 애플리케이션 내의 다른 구성요소들은 이 서비스를 활용하여 이벤트 기반 아키텍처 및 실시간 데이터 처리를 촉진할 수 있습니다.
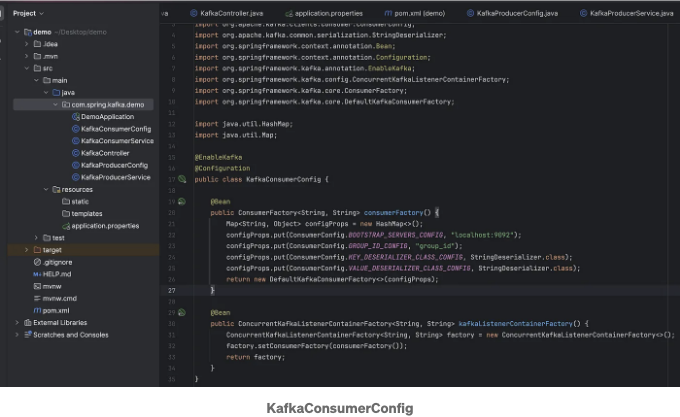
Kafka 소비자를 위한 구성 클래스를 생성하세요. KafkaConsumerConfig 클래스는 Spring Boot에서 Kafka 소비자 설정을 담당하는 중요한 구성 클래스입니다. 이 클래스는 @EnableKafka와 @Configuration으로 주석이 되어 있어, 응용 프로그램에 필수적인 Kafka 관련 구성을 제공함을 나타냅니다.
이 클래스에 정의된 주요 구성 요소 중 하나는 consumerFactory() 메서드에 의해 생성된 ConsumerFactory bean입니다. 이 메서드는 Kafka 소비자를 위한 필요한 구성 속성을 담은 HashMap을 설정합니다. 이러한 속성에는 Kafka 서버의 주소를 지정하는 BOOTSTRAP_SERVERS_CONFIG와 소비자 그룹 ID를 정의하는 GROUP_ID_CONFIG가 포함됩니다. 또한 KEY_DESERIALIZER_CLASS_CONFIG 및 VALUE_DESERIALIZER_CLASS_CONFIG 속성은 메시지의 키와 값에 대한 역직렬화기를 지정합니다. ErrorHandlingDeserializer는 역직렬화 오류 처리에 사용되며, TRUSTED_PACKAGES 속성은 지정된 패키지를 처리할 수 있는 역직렬화 프로세스를 보장합니다. 그런 다음 이 메서드는 이러한 속성으로 구성된 DefaultKafkaConsumerFactory를 반환합니다.
또 다른 중요한 구성 요소는 kafkaListenerContainerFactory() 메서드에 의해 정의된 ConcurrentKafkaListenerContainerFactory bean입니다. 이 팩토리는 Kafka 메시지를 처리하는 리스너 컨테이너를 생성하는 데 책임이 있습니다. setConsumerFactory()를 사용하여 이러한 컨테이너의 소비자 팩터리를 설정함으로써, Kafka 주제에서 메시지를 소비하기 위해 리스너 컨테이너가 올바르게 구성되도록 보장합니다.
간단히 말씀드리면, KafkaConsumerConfig 클래스는 Kafka 소비자가 Kafka 클러스터에 연결하고 들어오는 메시지를 역직렬화하며 효율적으로 오류를 처리할 수 있도록 필요한 구성 요소를 설정합니다. 이 구성은 응용 프로그램이 Kafka 토픽에서 메시지를 신속하게 소비할 수 있도록 보장하여 데이터 처리 파이프라인의 견고함과 신뢰성을 유지합니다.
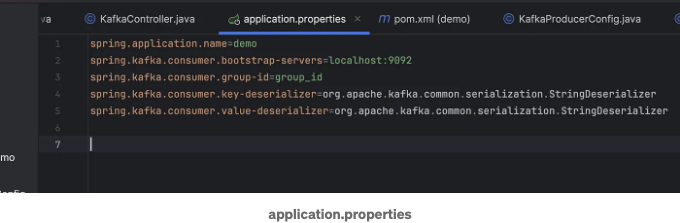
응용 프로그램 속성 파일에 다음 속성들이 있는지 확인하십시오.
메시지를 소비하는 서비스 클래스를 작성하세요:
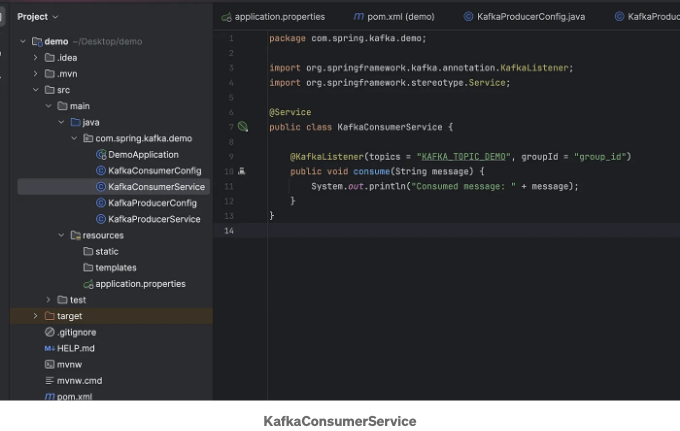
KafkaConsumerService 클래스에서는 Kafka 토픽에서 메시지를 수신하는 역할을 담당하는 서비스를 정의합니다. 이 클래스는 @Service로 주석이 달려 있어 Spring에서 관리되는 서비스 구성 요소임을 나타냅니다.
이 클래스의 핵심은 @KafkaListener로 주석이 달린 consume 메서드입니다. 이 주석은 메서드가 Kafka 토픽 KAFKA_TOPIC_DEMO에서 메시지를 수신해야 함을 지정합니다. 주석의 groupId 속성은 그룹 ID를 group_id로 설정하여 여러 소비자가 토픽에서 메시지를 처리하는 작업을 공유하여 작업을 조율할 수 있도록합니다.
consume 메서드 자체는 간단합니다: String 메시지를 매개변수로 사용하고 소비된 메시지를 콘솔에 출력합니다. 이 기본 설정은 Spring Boot 애플리케이션에서 Kafka 토픽에서 메시지를 소비하는 방법을 보여줍니다.
@KafkaListener를 사용하면 Spring Kafka가 Kafka에서 메시지 소비에 필요한 보일러플레이트 코드의 대부분을 추상화하여 Kafka를 Spring Boot 애플리케이션에 통합하는 것을 쉽게 만들어줍니다. 이 서비스는 KAFKA_TOPIC_DEMO 토픽에 발행된 모든 메시지가 이 소비자에 의해 수신되고 처리되도록 보장합니다.
샘플 컨트롤러로 테스트
Kafka를 통해 메시지를 보내는 REST 컨트롤러를 만듭니다. KafkaController 클래스에서는 간단한 REST 컨트롤러를 정의하여 HTTP 요청을 처리하고 Kafka 프로듀서 서비스와 상호 작용합니다. 이 클래스는 @RestController로 주석이 달린 Spring MVC 컨트롤러로, 모든 메서드가 뷰가 아닌 도메인 객체를 반환함을 나타냅니다. 이는 사실상 @Controller와 @ResponseBody의 결합입니다.
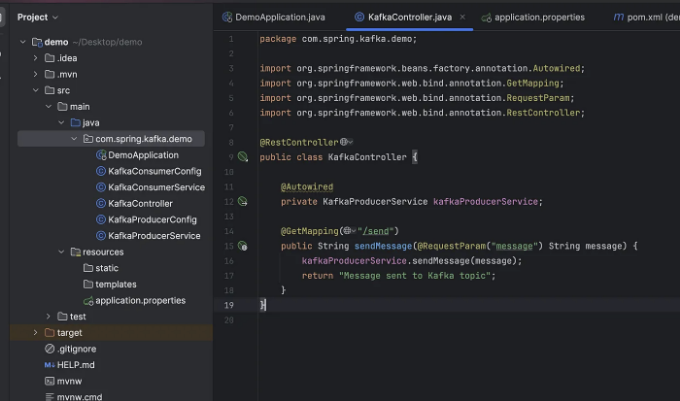
여기에는 이 클래스의 세부 내용이 있습니다:
- Autowiring KafkaProducerService: KafkaProducerService는 @Autowired를 사용하여 주입되며 해당 메서드를 사용하여 Kafka 토픽으로 메시지를 보낼 수 있습니다.
- sendMessage 메서드: sendMessage 메서드는 @GetMapping을 사용하여 /send URL에 매핑됩니다. message라는 요청 매개변수를 허용하며 이는 Kafka 토픽으로 보낼 메시지를 나타냅니다.
- 이 메서드는 요청 매개변수에서 받은 메시지를 전달하여 KafkaProducerService의 sendMessage 메서드를 호출합니다.
- 메시지를 보낸 후에는 메서드가 간단한 확인 문자열 "Message sent to Kafka topic"을 반환합니다.
이 설정을 사용하면 /send 엔드포인트로 GET 요청을 보내어 메시지 매개변수와 함께 Kafka 토픽으로 메시지를 보낼 수 있습니다. 예를 들어 다음 URL을 사용하여 메시지를 보낼 수 있습니다: http://localhost:8080/send?message=HelloKafka. 이 요청은 sendMessage 메서드를 트리거하고, 이 메서드는 "HelloKafka" 메시지를 KafkaProducerService에서 정의한 Kafka 토픽으로 보냅니다.
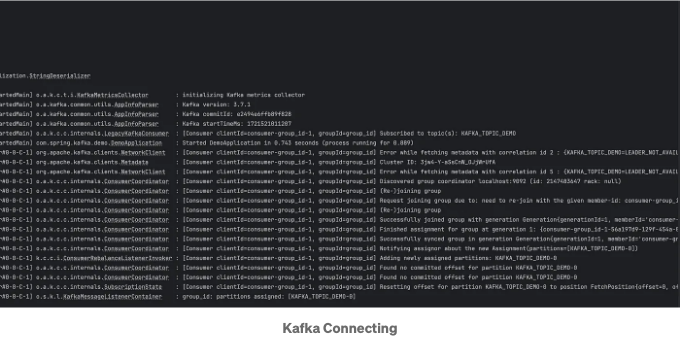
위 스크린샷에 나와 있는 로그 메시지에서 Kafka 소비자가 Kafka 클러스터에 연결하고 지정된 소비자 그룹에 가입하며 지정된 주제를 구독하는 프로세스에 대한 세부 정보가 나와 있습니다.
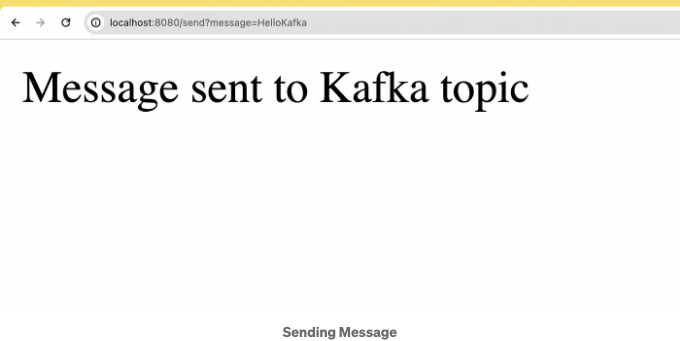
소비자가 수신한 메시지를 확인할 수 있습니다.
요약
이 기사에서는 Apache Kafka의 기본 개념, 사용 사례, 그리고 로컬 머신에서 설정하는 방법을 다루었습니다. 또한 Kafka를 Java의 Spring Boot 프로젝트와 통합하는 방법을 보여주었으며, 프로듀서와 컨슈머를 구성하는 세부적인 단계를 제공했습니다. 이 단계를 따라가면 Kafka를 활용하여 견고하고 확장 가능한 데이터 파이프라인과 스트리밍 어플리케이션을 구축할 수 있습니다.
결론
아파치 카프카는 실시간 데이터 파이프라인과 스트리밍 애플리케이션을 구축하는 강력한 도구입니다. 확장성, 고장 허용성, 그리고 높은 처리량으로 많은 조직들에게 인기가 있습니다. 로컬에서 Kafka를 설정하고 Spring Boot 애플리케이션과 통합하여 대량의 데이터를 효율적으로 처리할 수 있습니다. 간단한 메시징 시스템 또는 복잡한 이벤트 주도 아키텍처를 구축하더라도 Kafka를 사용하면 성공에 필요한 유연성과 성능을 활용할 수 있습니다.