
러스트는 종종 시스템 프로그래밍 언어로만 인식되지만 실제로 다재다능한 범용 언어입니다. 데스크톱 앱을 위한 Tauri, 프론트엔드 개발을 위한 Leptos, 백엔드 개발을 위한 Axum과 같은 프로젝트들은 러스트가 시스템 프로그래밍에 그치지 않고 더 다양하게 활용될 수 있다는 것을 보여줍니다.
저는 러스트를 배우기 시작할 때 웹 애플리케이션을 만들어 연습했어요. 주로 백엔드 엔지니어로 활동하고 있기 때문에 이 분야에 가장 익숙했습니다. 러스트는 웹 개발에 최적인 것을 빨리 깨달았죠. 그 기능들 덕분에 신뢰성 있는 애플리케이션을 만들 수 있습니다. 러스트가 웹 프로그래밍에 완벽한 이유에 대해 설명하겠습니다.
에러 처리
얼마 전에, 머신 러닝 열풍에 휩싸여 LLM 열풍 이전에 파이썬으로 시작했습니다. 머신 러닝 모델을 이용할 필요가 있어 Django REST API를 작성하기로 결정했습니다. Django에서 요청 본문을 얻으려면 다음과 같은 코드를 작성해야 합니다.
class User(APIView):
def post(self, request):
body = request.data
이 코드는 대부분의 경우 잘 작동합니다. 그러나 요청 본문을 잘못 보낸 경우 작동을 멈췄습니다. 데이터에 액세스하려고 시도하면 예외가 발생하여 500 상태 코드 응답이 발생했습니다. 접근이 예외를 유발할 수 있다는 점에 대해 전혀 인식하지 못했고 명확한 표시가 없었습니다.
Rust는 이를 다르게 처리하여 예외를 던지지 않고 오류를 결과 양식의 값으로 반환합니다. 결과에는 값과 오류가 모두 포함되어 있으며 값을 액세스하기 전에 오류를 처리해야 합니다.
let body: RequestBody = serde_json::from_slice(&requestData)?;
물음표(?)는 호출하는 함수에서 오류를 처리하고 오류를 한 수준 더 상위로 전파하려는 것을 나타냅니다.
나는 오류를 값으로 처리하는 모든 언어가 정확하게 하는 것이라고 믿습니다. 이 방식은 예상치 못한 놀라움이 없도록 코드를 작성할 수 있게 합니다. 파이썬 예시에서 한 것과 같이요.
기본 변경 불가능성
요즘, 제 동료 중 한 분이 오픈 소스 프로젝트 중 하나에서 작업을 했어요. 그분은 클라이언트 라이브러리를 다른 것으로 교체해야 했어요. 그 분이 사용한 코드는 이렇습니다:
newClient(
WithHTTPClient(httpClient), // &http.Client{}
WithEndpoint(config.ApiBasePath),
)
갑자기 연동 테스트에서 레이스 컨디션 오류가 발생했고, 그 분은 왜 그런지 이해할 수 없었어요. 도움을 요청해와서 문제를 추적해보니 이 코드 줄로 돌아왔어요. HTTP 클라이언트를 여러 클라이언트 사이에서 공유하고 있어서 오류가 발생했었어요. 여러 고루틴이 클라이언트를 읽고 WithHttpClient 함수가 클라이언트를 변형했기 때문에 일어난 문제였어요. 동일 자원에 독자와 작성자 스레드 모두가 있는 것은 Go에서 정의되지 않은 동작이나 패닉으로 이어질 수 있어요.
이는 또 다른 불쾌한 놀람이었어요. 그러나 Rust에서는 모든 변수가 기본적으로 변경할 수 없어요. 변수를 변경하려면 mut 키워드를 사용하여 명시적으로 지정해야 해요. API 클라이언트가 발생하는 일을 이해하고 예상치 못한 변형을 피하기 위해 이 도움이 돼요.
fn with_httpclient(client: &mut reqwest::Client) {}
매크로
자바나 파이썬과 같은 언어에서는 어노테이션이 있지만 러스트에서는 매크로를 사용합니다. 어노테이션은 Spring과 같은 환경에서 많은 일들이 반사(reflection)를 통해 자동으로 처리되는 우아한 코드를 만들 수 있습니다. 러스트 매크로는 덜 "마법(magic)" 같지만 더 깔끔한 코드를 만들어줍니다. 다음은 러스트 매크로의 예시입니다:
sqlx::query_as!(Student, "DELETE FROM student WHERE id = ? RETURNING *", id)
러스트에서의 매크로는 코드를 생성하고, 컴파일러가 빌드 과정에서 정확성을 확인하도록 하는 백그라운드에서 작동합니다. 매크로를 사용하면 컴파일 시간에 코드를 생성하여 실제 데이터베이스에 쿼리를 실행하는 코드를 생성하여 SQL 쿼리를 유효성 검사할 수 있습니다.
컴파일 시간에 코드의 정확성을 확인할 수 있는 능력은 특히 웹 개발에서 새로운 가능성을 열어줍니다. 웹 개발에서는 종종 원시 데이터베이스 문장이나 HTML 및 CSS 코드를 작성하는데, 이를 통해 버그가 적은 코드를 작성할 수 있습니다.
여기서 언급된 매크로는 선언적 매크로로, 러스트에는 다른 언어의 어노테이션과 유사한 절차적 매크로도 있습니다.
#[instrument(name = "UserRepository::begin")]
pub async fn begin(&self) {}
핵심 아이디어는 여전히 동일합니다: 코드를 백그라운드에서 생성하고 방법 전후에 일부 로직을 실행하여 더 견고하고 유지보수 가능한 코드를 보장합니다.
연결
다음은 Rust에서 우아한 코드를 확인해보세요:
let key_value = request.into_inner()
.key_value
.ok_or_else(|| ServerError::InvalidArgument("key_value must be set".to_string()))?;
이 더 간결한 방식과 비교해 볼 때:
Optional<KeyValue> keyValueOpt = request.getInner().getKeyValue();
if (!keyValueOpt.isPresent()) {
throw new IllegalArgumentException("key_value must be set");
}
KeyValue keyValue = keyValueOpt.get();
Rust에서는 연산을 연결하여 간결하고 가독성이 좋은 코드를 작성할 수 있습니다. 그러나 이러한 멋진 구문을 구현하려면 From과 같은 트레이트를 자주 구현해야 합니다.
기능적 기술자들은 이 방식을 인식하고 이를 극찬할 수 있습니다. 모든 functional 및 procedural 프로그래밍의 혼합을 허용하는 어떤 언어라도 옳은 길을 걷고 있다고 생각합니다. 이것은 개발자들에게 특정 사용 사례에 가장 적합한 방법을 선택할 수 있는 유연성을 제공합니다.
스레드 안전성
이미 누군가가 경쟁 조건으로 인해 프로덕션에서 패닉을 유발한 적이 있나요? 부끄럽지만, 저인 제가 그러했습니다. 네, 그것은 기술 문제였습니다. 동시에 메모리 주소를 변경하고 읽는 것을 놓치기 쉽습니다. 그러나 이 예시를 고려해 봅시다:
type repo struct {
m map[int]int
}
func (r *repo) Create(i int) {
r.m[i] = i
}
type Server struct {
repo *repo
}
func (s *Server) handleRequest(w http.ResponseWriter, r *http.Request) {
s.repo.Create(1)
}
여기서는 명시적으로 스레드를 시작하지 않고, 처음 보면 모든 것이 괜찮아 보입니다. 그러나 실제로는 HTTP 서버가 추상화에 의해 숨겨진 다중 스레드로 작동합니다. 웹 개발에서 이러한 추상화는 다중 스레딩과 관련된 잠재적인 문제를 숨길 수 있습니다. 이제 러스트로 동일한 기능을 구현해 봅시다:
struct repo {
m: std::collections::HashMap<i8, i8>
}
#[post("/maps")]
async fn crate_entry(r: web::Data<repo>) -> HttpResponse {
r.m.insert(1, 2);
HttpResponse::Ok().json(MessageResponse {
message: "good".to_string(),
})
}
이 프로그램을 컴파일하려고 하면 Rust 컴파일러가 오류를 발생시킵니다:

error[E0596]: cannot
borrow data in an
`Arc` as mutable
--> src\main.rs:117:5
|
117 | r.m.insert(1, 2);
| ^^^ cannot borrow as mutable
|
= help: trait `DerefMut` is required to modify through a dereference, but it is not implemented for `Arc<repo>
많은 사람들이 Rust의 오류 메시지가 보통 유용하다고 말하며, 그것은 종종 사실입니다. 그러나 이 경우에는 메시지가 혼란스럽고 즉시 명확하지 않을 수 있습니다. 다행히, 문제를 고치는 것은 간단하며 무엇을 해야 하는지 알고 있다면 됩니다: 작은 뮤텍스를 추가하기만 하면 됩니다:
struct repo {
m: HashMap<i8, i8>
}
#[post("/maps")]
async fn create_entry(r: web::Data<Mutex<repo>>) -> HttpResponse {
let mut map = r.lock().await();
map.m.insert(1, 2);
HttpResponse::Ok().json(MessageResponse {
message: "good".to_string(),
})
}
컴파일러가 이러한 문제를 피할 수 있도록 도와주어 코드를 안전하고 신뢰할 수 있게 유지해 주는 것이 정말 아름다운 일입니다.
Null Pointer Dereferencing
대부분의 사람들은 이 문제가 C에만 해당된다고 생각하지만, Java 또는 Go와 같은 언어에서도 마주칠 수 있습니다. 전형적인 문제의 예시를 살펴보겠습니다:
type valueObject struct {
value *int
}
func getValue(vo *valueObject) int {
return *vo.value
}
"값을 사용하기 전에 값이 nil인지 확인하십시오." 라고 말할 수 있을 것입니다. 이는 Go에서 가장 큰 함정 중 하나입니다 - 포인터 메커니즘입니다. 때로는 메모리 할당을 최적화하고 때로는 선택적 값에 포인터를 사용합니다.
인터페이스를 다룰 때 특히 null 포인터 참조의 위험이 명확해집니다.
type Repository interface {
Get() int
}
func getValue(r Repository) int {
return r.Get()
}
func main() {
getValue(nil)
}
많은 언어에서 인터페이스에 대한 유효한 옵션으로 null 값을 전달하는 것이 가능합니다. 일반적으로 코드 리뷰에서 이를 잡지만, null 인터페이스가 개발 단계에 들어간 경우도 본 적이 있습니다. Rust에서는 이러한 문제가 간단히 불가능하기 때문에 우리의 실수로부터 추가적으로 보호할 수 있습니다:
trait Repository {
fn get(&self) -> i32;
}
fn get_value(r: impl Repository) -> i32 {
r.get()
}
fn main() {
get_value(std::ptr::null());
}
컴파일되지 않는다는 것을 언급하지 않을 수 없습니다.
영제화의 중요성
저는 포트와 어댑터에 대한 큰 팬입니다. 여기에는 몇 가지 추상화가 포함되어 있습니다. 복잡성에 따라 이러한 추상화는 응용 프로그램 내에서 명확한 경계를 생성하여 단위 테스트 가능성과 장기적인 유지 보수성을 향상시키는 데 필요할 수 있습니다. 비평가들의 한 주장은 성능이 감소한다는 것인데, 특정 인터페이스 구현이 컴파일 시간에 결정되지 않아 동적 디스패치가 종종 필요하기 때문입니다. Java 예시를 살펴보겠습니다:
@Service
public class StudentServiceImpl implements StudentService {
private final StudentRepository studentRepository;
@Autowired
public StudentServiceImpl(StudentRepository studentRepository) {
this.studentRepository = studentRepository;
}
}
Spring은 많은 작업을 자동으로 처리해 줍니다. 여기에는 @Autowired 주석을 사용한 의존성 주입 기능도 포함됩니다. 앱이 시작되면 Spring은 클래스 경로 스캐닝과 리플렉션을 수행합니다. 그러나 이 편의성은 성능 비용이 발생한다는 것을 의미합니다.
Rust는 제로 비용 추상화로 알려진 것 덕분에 성능 패널티 없이 이러한 깔끔한 추상화를 만들 수 있습니다:
struct ServiceImpl<T: Repository> {
repo: T,
}
trait Service {}
fn new_service<T: Repository>(repo: T) -> impl Service {
ServiceImpl { repo: repo }
}
이러한 추상화는 컴파일 타임에 처리되어 런타임 성능 비용이 없음을 보장합니다. 이를 통해 우리는 성능을 희생하지 않고도 깨끗하고 효율적인 코드를 유지할 수 있습니다.
데이터 변환
기업 애플리케이션에서는 복잡한 비즈니스 요구 사항을 처리하기 위해 종종 포트 및 어댑터 패턴을 사용합니다. 이 패턴은 데이터를 다른 레이어에 필요한 표현으로 변환하는 것을 포함합니다. 우리는 사용자 데이터를 비동기 통신의 이벤트로 받거나 동기 통신의 요청으로 받을 수 있습니다. 이 데이터는 도메인 모델로 변환되고 서비스 및 어댑터 레이어를 통해 전달됩니다.
그럼 이제 이 질문이 생깁니다: 변환 로직은 어디에 위치해야 할까요? 도메인 패키지에 있어야 할까요? 아니면 데이터가 매핑되는 패키지에 위치해야 할까요? 데이터를 변환하는 메서드는 어떻게 호출해야 할까요? 이러한 질문들은 종종 코드베이스 전체에 일관성이 떨어지게 만듭니다.
Rust는 From 트레이트를 사용하여 데이터 변환을 처리하는 명확한 방법을 제공하는 데 뛰어납니다. 어댑터에서 도메인으로 데이터를 변환해야 할 경우, 간단히 어댑터에서 From 트레이트를 구현하면 됩니다:
impl From<UserRequest> for domain::DomainUser {
fn from(user: UserRequest) -> Self {
domain::DomainUser {}
}
}
impl From<domain::DomainUser> for UserResponse {
fn from(user: domain::DomainUser) -> Self {
UserResponse {}
}
}
fn create_user(user: UserRequest) -> Result<()> {
let domain_user = domain::upsert_user(user.into());
send_response(domain_user.into())?;
Ok(())
}
테이블 태그를 마크다운 형식으로 변경해보세요.
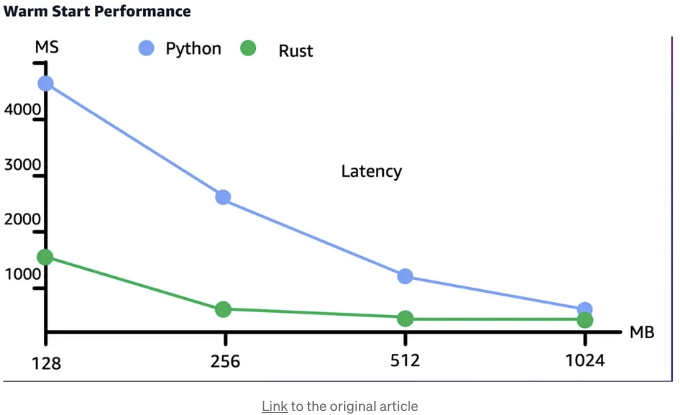
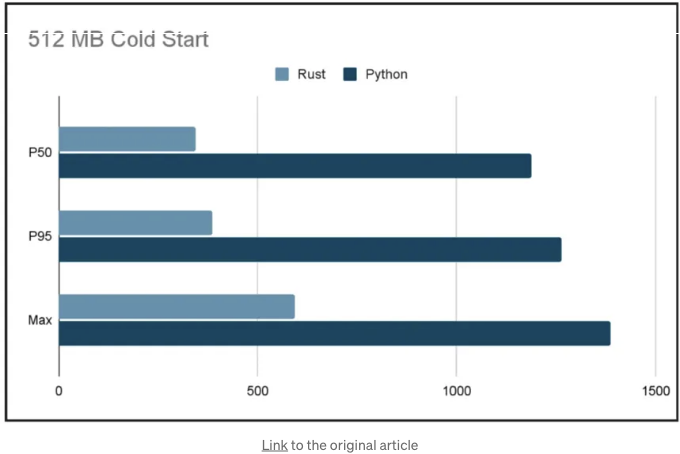
AWS 계정의 모든 버킷을 나열하고 각 버킷의 지역을 결정하는 람다 함수를 상상해보세요. 어떤 REST API 호출을 하고 for 루프를 사용하더라도 성능적으로 큰 차이가 없을 것이라고 생각할 수 있습니다. 어떤 언어라도 이 작업을 합리적으로 처리할 수 있을 거라고 생각하시죠?
그러나 테스트 결과, Rust가 Python보다 이 작업을 빠르게 수행하고 실행 시간 당 훨씬 적은 메모리를 사용한다는 것을 보여줍니다. 실제로, 그들은 100만 호출 당 6달러를 절약했습니다.
웹 및 Kubernetes 배경에서 사용자 부하에 따라 스케일 업 및 다운하는 경험으로 효율적인 자원 사용이 비용을 절약하고 시스템 신뢰성을 향상시킨다는 것을 확인할 수 있어요. 각 복제본 당 더 적은 자원 사용은 한 노드에 더 많은 컨테이너를 수용할 수 있다는 것을 의미해요. 각 복제본이 더 많은 요청을 처리할 수 있다면 전체적으로 더 적은 복제본이 필요하게 됩니다. 높은 성능과 효율적인 자원 활용은 비용 효율적이고 신뢰할 수 있는 시스템을 구축하는 데 중요해요.
마치며
웹 개발 분야에서 Rust로 3년간 작업하면서 정말 만족스러웠어요. 비동기 코드 또는 매크로를 작성하는 것과 같은 도전적인 측면은 사용하는 라이브러리에서 잘 처리돼요. 예를 들어, Tokio 라이브러리를 살펴봤다면, 상당히 복잡하다는 것을 아실 거예요. 그러나 비즈니스 로직에 집중하고 데이터베이스 또는 메시지 큐와 같은 외부 시스템과 상호 작용하는 웹 개발에서는 Rust의 우수한 안전 기능을 활용하면서 더 간단한 부분을 즐길 수 있어요.

루스트를 한 번 시도해 보세요. 즐기면서 더 나은 프로그래머가 될 수도 있을 거예요!