
어떤 프로그램은 결코 실패하지 않을까요?
어쩌면 이러한 프로그램은 프로그래머의 꿈 속에서만 존재하는 것이겠죠. 프로그래밍 언어와 소프트웨어가 발전함에 따라, 예외가 항상 우리와 함께해 왔습니다. 예상치 못한 상황을 적절하게 처리하는 것은 프로그램 신뢰성을 보장하는 데 중요합니다.
자바 언어의 탄생부터 비교적 포괄적한 예외 처리 메커니즘을 제공해 왔습니다. 이것이 자바가 그만큼 흔해지게 된 이유 중 하나인데요 – 신뢰할 수 있는 프로그램을 작성하고 유지하는 데 큰 장벽을 낮춰 주기 때문입니다. 오늘날, 예외 처리 메커니즘은 현대 프로그래밍 언어에서 표준적으로 적용되고 있습니다.
오늘의 질문
예외(Exception)와 에러(Error)를 비교하고, 런타임 예외와 체크 예외의 차이를 설명해주세요.
전형적인 답변
Exception과 Error는 모두 Throwable의 하위 클래스입니다. Java에서는 Throwable의 인스턴스만이 던져지거나 잡힐 수 있어 예외 처리 메커니즘에서 기본적인 타입입니다.
예외(Exception)와 에러(Error)는 Java 플랫폼 디자이너가 다른 종류의 문제들을 분류한 것을 반영합니다. 예외는 일반 프로그램 실행 중에 예상되고, 잠재적으로 관리 가능한 문제를 나타냅니다. 이러한 문제들은 적절히 잡고 처리해야 합니다.
에러는 반면에, 일반적인 조건에서 일어나기 어려운 상황을 가리킵니다. 대부분의 에러 인스턴스는 프로그램(예를 들어 JVM 자체)을 비정상적이고 회복 불가능한 상태로 이끌 수 있습니다. 이러한 비정상 상황이기 때문에 일반적으로 잡고 처리하지 않습니다. 일반적인 예시로는 OutOfMemoryError 및 에러의 서브클래스들이 있습니다.
예외는 확인된 예외(checked exceptions)와 확인되지 않은 예외(unchecked exceptions)로 나뉩니다. 확인된 예외는 소스 코드에서 명시적으로 처리하거나 선언해야 하며, 이것은 컴파일 시간 확인의 일부입니다. 확인되지 않은 예외 또는 런타임 예외는 NullPointerException 및 ArrayIndexOutOfBoundsException과 같은 로직 오류로, 코딩 방법을 통해 피할 수 있는 오류로 컴파일 시간에 강제되지 않습니다.
시험 포인트들
Exception과 Error의 차이점을 분석하면 Java의 핸들링 메커니즘에 대한 개념적 이해를 확인할 수 있어요. 전반적으로, 이는 개념을 명확히 이해하는 데 관한 것이에요.
일상적인 프로그래밍에서 예외를 효과적으로 처리하는 것은 기술의 표시에요. 두 가지 측면을 잘 이해하는 것이 중요해요:
- Throwable, Exception 및 Error의 디자인과 분류를 이해하는 것. 이는 널리 사용되는 서브클래스를 알고 사용자 정의 예외를 만드는 방법도 포함돼요.
- Error, Exception 및 RuntimeException의 특정 예제에 친숙해지는 것. 전형적인 예제를 나열한 간단한 클래스 다이어그램은 참고용으로 유용하며 기본적인 이해를 확인하는 데 도움이 될 수 있어요.
많은 면접관들은 더 깊이 들어가서, 어떤 Error 또는 Exception에 익숙한지 묻을 수도 있어요. 이러한 개념에 대한 기본 개념을 갖고 있다면 도움이 될 거예요.
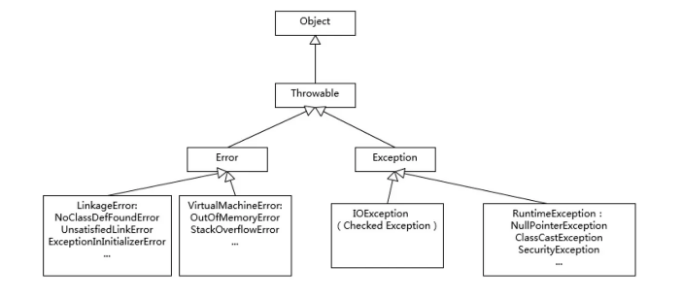
일부 하위 유형 중 NoClassDefFoundError와 ClassNotFoundException의 차이와 같은 것에 집중하는 것이 유용합니다. 이는 고전적인 입문 주제입니다.
둘째, Java에서 Throwable을 처리하는 요소와 실천 방법을 이해하는 것이 중요합니다. 기본 구문 및 try-catch-finally 블록, throw 및 throws 키워드와 같은 것을 숙달하는 것이 필수입니다. 또한 일반적인 시나리오를 처리하는 방법을 알아야 합니다.
예외 처리 코드는 상당히 장황할 수 있으며 종종 반복적인 catch 블록이나 finally 블록에서 리소스 정리가 필요합니다. Java 언어의 진화로 인해 try-with-resources와 여러 catch 블록과 같은 더 편리한 기능이 도입되었습니다. 예를 들어 컴파일 중에 Java 컴파일러는 기본 처리 논리를 자동으로 생성하여 규약에 따라 AutoCloseable이나 Closeable을 구현하는 개체를 자동으로 닫습니다.
try (BufferedReader br = new BufferedReader(…);
BufferedWriter writer = new BufferedWriter(…)) {// Try-with-resources
// do something
catch ( IOException | XEception e) {// Multiple catch
// Handle it
}
지식 확장
이전 토론은 대부분 개념적 측면을 다뤘습니다. 이제 실용적 선택 사항에 대해 이야기하고 일부 코드 예제와 함께 분석해 보겠습니다.
첫 번째로 시작해 봅시다. 다음 코드에 반영된 예외 처리 문제는 무엇일까요?
try {
// 비즈니스 코드
// …
Thread.sleep(1000L);
} catch (Exception e) {
// 무시하기
}
이 코드는 간결하지만 예외 처리의 두 가지 기본 원칙을 위반합니다.
첫째로, Exception과 같은 일반적인 예외를 catch 하는 대신 Thread.sleep()에 의해 발생하는 InterruptedException과 같은 특정 예외를 catch 하는 것이 좋습니다.
일상적인 개발 및 협업에서는 코드를 쓰는 것보다 읽는 일이 더 많습니다. 소프트웨어 공학은 협업의 예술이므로 우리의 코드를 가능한 한 정보적으로 만드는 의무가 있습니다. Exception과 같은 일반적인 예외는 우리의 의도를 혼동시킵니다. 또한, 우리는 프로그램이 우리가 원치 않는 예외를 catch하지 않도록 해야 합니다. 예를 들어 RuntimeException이 catch되는 대신 전파되는 것이 좋을 수도 있습니다.
또한 주의 깊게 고려하지 않는 한 Throwable 또는 Error을 잡지 마십시오. OutOfMemoryError를 올바르게 처리하기가 어려울 수 있습니다.
두 번째로, 예외를 삼키지 마십시오. 이는 매우 진단하기 어려운 문제로 이어질 수 있기 때문에 예외 처리에서 매우 중요합니다.
예외를 삼키는 것은 종종 코드가 실패하지 않을 것이라는 가정이나 예외를 무시해도 문제가 되지 않을 것이라는 가정에 기반을 둔 것입니다. 그러나 제품 코드에서는 이러한 가정을 절대 하지 마십시오!
만약 우리가 예외를 throw하거나 Logger를 사용하여 로깅하지 않는다면, 프로그램이 예측할 수 없이 나중에 갑자기 종료될 수 있습니다. 그때 예외가 발생한 위치를 판별하고 원인을 파악하기 어려워집니다.
이제 두 번째 코드 조각을 살펴보겠습니다.
try {
// 비즈니스 코드
// …
} catch (IOException e) {
e.printStackTrace();
}
실험용 코드로서, 이 코드 조각은 본질적으로 문제가 있는 것은 아니지만 실제 운영 코드에서는 일반적으로 이러한 처리 방식이 허용되지 않습니다. 그 이유에 대해 생각해 보겠습니다.
먼저, printStackTrace() 메서드의 문서를 살펴보겠습니다. "이 throwable 및 해당 백트레이스를 표준 오류 스트림에 출력합니다."라고 시작합니다. 여기서 문제는 약간 더 복잡한 운영 시스템에서는 표준 오류(STERR)가 이상적인 출력 옵션이 아니라는 것입니다. 출력이 어디에 정확히 도착하는지 판단하기 어렵기 때문입니다.
분산 시스템에서 특히 예외가 발생하더라도 스택 추적이 없으면 진단에 장벽이 생깁니다. 따라서 로그에 자세한 정보를 출력하기 위해 생성 로깅 시스템을 사용하는 것이 좋습니다.
이제 "일찍 던지고, 나중에 잡기" 원칙을 이해하기 위해 다음 코드 조각을 살펴보겠습니다.
public void readPreferences(String fileName){
//...작업 수행...
InputStream in = new FileInputStream(fileName);
//...환경 설정 파일 읽기...
}
만약 fileName이 null이라면 프로그램은 NullPointerException을 throw합니다. 그러나 문제가 즉시 드러나지 않기 때문에 스택 추적이 상당히 혼란스러울 수 있으며 상대적으로 복잡한 디버깅이 필요할 수 있습니다. 이 NPE는 예시일 뿐이며, 실제 제품 코드에서 환경 설정 실패 등 여러 시나리오가 발생할 수 있습니다. 감지 지점에서 예외를 일찍 던지면 문제가 더 명확하고 직접적으로 해결됩니다.
코드를 수정하여 "조기 throw"로 변경할 수 있어요. 이렇게 하면 예외 정보가 훨씬 명확해져요.
public void readPreferences(String filename) {
Objects.requireNonNull(filename);
// 다른 작업 수행...
InputStream in = new FileInputStream(filename);
// 환경 설정 파일 읽기...
}
"나중에 catch"에 대해 말하자면, 예외를 처리한 후에 무엇을 해야 할지 고민하는 상황이 흔해요. 이전에 언급한 것처럼, 가장 나쁜 접근 방법은 예외를 "삼켜 버리는" 것인데, 그렇게 되면 문제가 숨겨져 버릴 수 있어요. 예외를 어떻게 처리해야 할지 모르겠다면, 원래 예외의 원인 정보를 유지한 채로 다시 던지거나 새로운 예외를 던질 수 있어요. 명확한 (비즈니스) 로직이 있는 높은 수준에서는 적절한 처리 방법이 보통 보다 분명해져요.
가끔은 커스텀 예외를 정의해야 할 때가 있어요. 그럴 때는 충분한 정보를 제공하는 것 외에도 다음을 고려해 보세요:
- Checked Exception으로 정의해야 하는지 여부는 이 유형이 예외적인 상황에서 회복하도록 설계되었기 때문입니다. 예외 설계자로서 종종 이러한 상황을 분류할 정보가 충분합니다.
- 진단 정보가 충분하게 포함되어 있는지 확인하되, 민감한 정보는 포함하지 않도록 주의해야 합니다. 예를 들어 Java 표준 라이브러리에서 java.net.ConnectException은 "Connection refused (Connection refused)"와 같은 에러 메시지를 제공하지만 기계 이름, IP 주소 또는 포트와 같은 구체적인 세부 정보를 제공하지 않아 정보 보안에 중요한 고려 사항입니다. 마찬가지로, 민감한 사용자 데이터는 일반적으로 로그에 출력되어서는 안 됩니다.
산업 내에서 Java의 Checked Exception이 설계 결함일 수도 있다는 논란이 있습니다. 비판자들은 다음을 주장합니다:
- Checked Exception 뒤에 있는 가정은 우리가 예외를 잡아서 회복한다는 것입니다. 그러나 대부분의 경우 회복이 불가능합니다. Checked Exception의 사용은 원래의 설계 의도에서 크게 벗어났습니다.
- Checked Exception은 함수형 프로그래밍과 호환되지 않습니다. Lambda/Stream 코드를 사용해본 경우에는 이를 잘 이해하게 될 것입니다.
- Spring이나 Hibernate와 같은 많은 오픈 소스 프로젝트가 Checked Exception을 피하는 방법을 채택했습니다. 이 경향은 Scala와 같은 새로운 프로그래밍 언어의 설계에도 반영되고 있습니다.
관심이 있다면 아래를 참고하세요:
물론, 일부 사람들은 지나치게 수정할 필요가 없다고 믿습니다. 실제로 IO 및 네트워크 관련 예외와 같이 회복이 가능한 예외가 몇 가지 있습니다. 자바는 포괄적인 산업 실무를 통해 고품질 소프트웨어를 구축하는 능력을 입증했습니다. 이 주제를 더 깊게 들어가지는 않겠습니다.
성능 관점에서, 자바의 예외 처리 메커니즘에는 두 가지 비용이 많이 드는 측면이 있습니다:
- try-catch 블록의 성능 오버헤드: try-catch 블록을 사용하면 성능 오버헤드가 추가됩니다. 보다 구체적으로 말하면, JVM의 코드 최적화 능력에 영향을 줄 수 있습니다. 필요한 코드 세그먼트에서만 예외를 처리하고 하나의 try 문으로 큰 코드 블록을 묶지 않는 것이 좋습니다. 게다가 예외를 사용하여 코드의 흐름을 제어하는 것은 일반적으로 조건문(예: if/else 또는 switch)을 사용하는 것보다 비효율적입니다.
- 예외 생성 시 스택 스냅샷: 자바에서 예외를 인스턴스화할 때마다 스택의 스냅샷이 촬영되는데, 이는 비교적 무거운 작업입니다. 예외가 매우 빈번히 발생하면 이러한 비용이 상당해질 수 있습니다.
극도의 성능이 필요한 저수준 라이브러리의 경우, 스택 트레이스를 포착하지 않는 예외를 생성하는 방법이 있습니다. 이 방법은 스택 트레이스가 미래에 필요할지를 예측할 수 있다는 가정 때문에 논란이 될 수 있습니다. 이는 소규모 시나리오에서는 가능할 수 있지만, 대규모 프로젝트에서는 현명한 선택이 아닐 수 있습니다. 스택 트레이스 정보가 필요하지만 수집되지 않으면, 특히 마이크로서비스와 같은 분산 시스템에서 복잡한 시스템에서 문제를 진단하는 것이 훨씬 어려워집니다.
서비스가 성능 저하나 처리량 감소를 겪을 때 가장 빈번하게 발생하는 예외를 분석하면 소중한 통찰을 얻을 수도 있습니다.
결론
오늘은 Java의 예외 처리 메커니즘에 대한 간단한 요약을 제공했습니다. 일반적인 개념적 문제에서 시작하여 널리 받아들여지는 모범 사례들과 최신 산업의 예외 처리에 대한 합의를 분석했고, 코드 예제와 함께 설명했습니다. 마지막으로, 예외와 관련된 성능 부담에 대해 논의하면서 이 정보가 도움이 되기를 바랍니다.
