
이 글 "Spring Boot: 사용 가능한 메모리보다 많은 데이터를 쿼리 처리하는 REST 엔드포인트 다루기"에서는 Spring Boot에서 사용 가능한 메모리보다 많은 데이터를 반환하는 REST 엔드포인트를 어떻게 만들 수 있는지 보여줍니다. 이 글에서는 JPA 대신 Spring Boot JDBC를 사용하여 이를 어떻게 달성할 수 있는지 살펴봅시다.
시나리오
같은 데이터베이스를 재사용하여, 백만 개의 주문과 500만 개 이상의 주문 항목을 갖습니다:
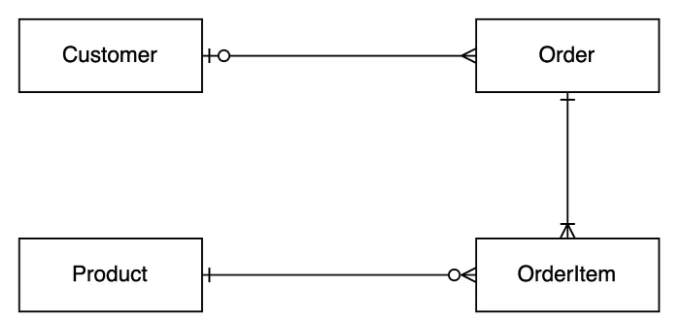 지금은 데이터를 저장하는 방법을 간소화하기 위해 평평한 DTO를 사용해봅시다.
지금은 데이터를 저장하는 방법을 간소화하기 위해 평평한 DTO를 사용해봅시다.
@Data
public class ReportDto {
private final Long orderId;
private final LocalDate date;
private final String customerName;
private final BigDecimal totalAmount;
private final String currency;
private final String status;
private final String paymentMethod;
private final Long productId;
private final String productName;
private final Integer quantity;
private final BigDecimal price;
private final BigDecimal itemTotalAmount;
}
다음 SQL 쿼리를 사용하여 데이터를 가져올 것이며, JdbcTemplate 클래스를 사용하여 쿼리를 실행할 것입니다:
SELECT o.id, o.date, c.first_name, o.total_amount, o.currency, o.status,
o.payment_method, oi.product_id, p.name, oi.quantity, oi.price,
oi.total_amount
FROM orders o
JOIN customers c ON c.id = o.customer_id
JOIN order_items oi ON oi.order_id = o.id
JOIN products p ON p.id = oi.product_id
시도 1: queryForList 메서드 사용
queryForList 메서드를 사용하여 쿼리에서 반환된 각 필드-값 쌍을 포함하는 맵의 리스트를 반환하는 방법은 작동하지 않았습니다.
@Controller
@RestController
@RequiredArgsConstructor
public class ReportController {
private final ReportService reportService;
@GetMapping("/v4/report")
public ResponseEntity<List<ReportDto>> report4() {
final var body = reportService.getResult();
return ResponseEntity.ok(body);
}
}
@Service
@RequiredArgsConstructor
public class ReportService {
private final JdbcTemplate jdbcTemplate;
public List<ReportDto> getResult() {
List<Map<String, Object>> queryResult = jdbcTemplate.queryForList(QUERY);
return toReportDto(queryResult);
}
}
우리가 기대한 대로, 각 항목이 맵인 리스트에 전체 결과를 저장하면 다음 오류가 발생합니다:
서블릿 [dispatcherServlet]의 서비스()이 경로가 있는 컨텍스트에서
예외를 던짐 [핸들러 디스패치 실패: java.lang.OutOfMemoryError:
Java heap space]
java.lang.OutOfMemoryError: Java heap space
시도 2: RowMapper를 사용한 query 메서드 사용
일반 결과를 반환하고 이를 DTO로 매핑하는 대신, 쿼리 처리 중에 RowMapper를 사용하여 매핑합시다.
@Controller
@RestController
@RequiredArgsConstructor
public class ReportController {
private final ReportService reportService;
@GetMapping("/v5/report")
public ResponseEntity<List<ReportDto>> report5() {
final var body = reportService.getResult();
return ResponseEntity.ok(body);
}
}
@Service
@RequiredArgsConstructor
public class ReportService {
private final JdbcTemplate jdbcTemplate;
public List<ReportDto> getResult() {
return jdbcTemplate.query(QUERY, (rs, rowNum) -> mapToReportDto(rs));
}
}
이 접근 방식은 작동하는 것 같지만, 쿼리는 DTO로 매핑하기 전에 모든 데이터를 읽기 때문에 메모리 부족 오류가 발생할 수 있습니다.
시도 3: queryForStream 메서드 사용
다음 시도는 데이터베이스에서 스트림을 반환할 수 있는 queryForStream 메서드를 사용하는 것입니다. 그러나 이 전 시도와 유사한 구현이므로 성공하지 못했습니다.
@Controller @RestController @RequiredArgsConstructor public class ReportController {
private final ReportService reportService;
@GetMapping("/v6/report")
public ResponseEntity<List
@Service @RequiredArgsConstructor public class ReportService { private final JdbcTemplate jdbcTemplate;
public List
Try 4: Using the query Method with RowCallbackHandler
In JdbcTemplate, we can use a query method that accepts a RowCallbackHandler to process rows one-by-one and map them to the DTO, preventing the memory waste of holding both the query result and the DTOs simultaneously. Additionally, let’s set the fetch size to 1000, which makes JdbcTemplate fetch data in chunks of 1000 results instead of all at once.
@Controller
@RestController
@RequiredArgsConstructor
public class ReportController {
private final ReportService reportService;
@GetMapping("/v7/report")
public ResponseEntity<List<ReportDto>> report7() {
final var body = reportService.getResult();
return ResponseEntity.ok(body);
}
}
@Service
@RequiredArgsConstructor
public class ReportService {
private final JdbcTemplate jdbcTemplate;
public List<ReportDto> getResult() {
jdbcTemplate.setFetchSize(1000);
final var result = new ArrayList<ReportDto>();
jdbcTemplate.query(
QUERY,
rs -> {
while (rs.next()) {
result.add(mapToReportDto2(rs));
}
});
return result;
}
}
하지만, 이 방법만으로는 충분하지 않습니다.
마지막으로: RowCallbackHandler와 query 메서드를 사용하여 결과 스트리밍하기
문제를 해결하기 위해 데이터베이스에서 데이터를 쿼리하는 방법을 변경하는 것 이상이 필요합니다. 데이터를 스트리밍해야 합니다. 변경 사항은 다음과 같습니다:
- 행별로 쿼리 결과를 처리할 수 있는 JdbcTemplate 쿼리 메서드 사용.
- 클라이언트에 데이터를 청크로 전송할 수 있도록 REST 엔드포인트에서 StreamingResponseBody 클래스 사용.
@Controller
@RestController
@RequiredArgsConstructor
public class ReportController {
private final ReportService reportService;
@GetMapping("/v7/report")
public ResponseEntity<StreamingResponseBody> report7() {
final var body = reportService.getResult();
return ResponseEntity.ok(body);
}
}
@Service
@RequiredArgsConstructor
public class ReportService {
private final JdbcTemplate jdbcTemplate;
private final ObjectMapper objectMapper = new ObjectMapper();
public StreamingResponseBody getResult() {
jdbcTemplate.setFetchSize(1000);
return outputStream -> {
jdbcTemplate.query(
QUERY,
rs -> {
while (rs.next()) {
try {
var json = objectMapper.writeValueAsString(mapToReportDto(rs));
outputStream.write(json.getBytes(StandardCharsets.UTF_8));
} catch (final IOException e) {
throw new RuntimeException(e);
}
}
});
};
}
}
여기에는 다음이 있습니다:
- 컨트롤러는 결과 데이터를 스트리밍합니다.
- 서비스는 가져올 행 수를 1000으로 설정하여 쿼리가 한 번에 데이터베이스에서 1000개의 행을 반환하도록합니다. 그렇지 않으면 JdbcTemplate 클래스가 한꺼번에 모든 데이터를 가져오려고 하여 메모리 부족 오류가 발생합니다.
- 각 결과 세트에 대해 DTO로 매핑하고 JSON으로 변환한 후 출력 스트림에 작성합니다.
우리의 목표를 달성했습니다. 이 엔드포인트는 30초 안에 500 만 레코드를 반환할 수 있었습니다!
결론
JPA 대신 JdbcTemplate을 사용하면 DTO 매핑과 같은 몇 가지 작업을 수동으로 수행해야하지만, 데이터를 가져오기 위한 복잡한 SQL 쿼리를 간단하게 만들어 줍니다.
저는 항상 JPA를 사용하는 것을 추천합니다. 왜냐하면 더 쉽게 구현할 수 있으며 일부 오타를 피할 수 있기 때문입니다. 그러나 JdbcTemplate을 사용하면 극도로 복잡한 쿼리를 쉽게 작성하고 빠르게 실행할 수 있습니다.
데이터를 가져오기 위해 사용하는 프레임워크에 관계없이 어떠한 종류의 메모리 문제도 해결할 수 있는 도구를 갖고 있습니다.