Python Shiny 라이브러리는 Python에서 인터랙티브 웹 애플리케이션을 구축하기 위한 프레임워크입니다.
RStudio에서 개발된 이 라이브러리는 R을 위한 Shiny 라이브러리를 개발한 동일한 팀에 의해 개발되었으며, 특히 데이터 과학자와 분석가들에게 유용합니다. 이 라이브러리를 사용하면 광범위한 프론트엔드 개발 기술이 없어도 인터랙티브 대시보드와 애플리케이션을 구축할 수 있습니다.
Python Shiny가 할 수 있는 일
- 대화식 데이터 시각화: Python Shiny를 사용하면 사용자가 입력에 따라 동적으로 업데이트되는 대화식 시각화를 만들 수 있습니다. 이는 탐색적 데이터 분석과 사용자 상호 작용에 매우 유용합니다.
- 대시보드 생성: Python Shiny를 사용하면 여러 데이터 소스와 시각화를 종합한 포괄적인 대시보드를 만드는 것이 간단해집니다.
- 대화식 애플리케이션: Python Shiny를 사용하면 사용자가 실시간으로 데이터와 상호 작용할 수 있는 애플리케이션을 개발할 수 있습니다. 예를 들어 데이터 집합 필터링, 통계 모델 적용, 보고서 생성 등이 있습니다.
- 원형 및 공유: 데이터 과학자들은 빠르게 데이터 응용 프로그램의 프로토타입을 만들고 누구에게나 공유할 수 있습니다.
- Plotly 통합: Plotly와의 통합을 통해 Shiny는 다양한 대화식 지도와 차트를 제공할 수 있습니다.
사용하기 얼마나 쉬운가요? 간단한 데이터 세트와 기본 대화식 데이터 시각화를 사용하여 한 번 테스트해보겠습니다.
데이터세트
이 연습에서는 아주 간단한 데이터 세트인 전 세계 행복 데이터를 사용하겠습니다. 여기에서 찾을 수 있습니다.
저는 world_happiness_2023.csv 파일을 다운로드하여 압축을 해제하고 저장했습니다.
이 CSV 파일에서 우리에게 중요한 필드는 다음과 같습니다:
- Country name — 행복 지수가 있는 각 국가의 이름
- year — 기록된 데이터의 연도
- Life Ladder — 실제 행복 지수를 포함하는 필드 (값이 클수록 국가는 더 행복합니다).
이 데이터셋을 사용하면 각 국가를 전 세계적으로 비교하는 도구를 사용하여 지역별 비교를 볼 수 있습니다.
시작하기에 좋은 도구는 등치지도입니다.
등치지도는 미리 정의된 영역(예: 국가) 내에서 의 평균 값을 나타내기 위해 음영이나 색상의 차이를 활용합니다.
예를 들어, 우리는 더 어두운 음영을 사용하여 더 높은 행복 지표를 가진 국가를 나타낼 수 있습니다.
그래서 Shiny를 활용하여 상호작용하는 데이터 시각화를 만들어 봅시다. 두 가지 구성 요소가 있는데요.
- 드롭다운 메뉴 — 사용자가 연도를 선택할 수 있게 합니다 (이 데이터 셋은 2005년부터 2022년까지의 데이터를 포함하고 있습니다).
- 전역 코로플레스 맵 — 세계지도상 각 국가의 값을 표시합니다 (선택한 연도에 대해).
그리고 이를 모듈화된 방식으로 진행하겠습니다. 먼저 필요한 모든 라이브러리 및 데이터셋을 로드합니다.
1. 라이브러리 및 데이터셋 로드
이 애플리케이션이 성공적으로 실행되려면 세 개의 주요 라이브러리가 필요합니다. 애플리케이션을 실행하기 전에 각 라이브러리를 설치해 놓으셨는지 확인해주세요 (나중 단계에서 자세히 다루겠습니다).
import pandas as pd
import plotly.express as px
from shiny import App, render, ui, reactive
# 필요한 라이브러리를 가져와서 Pandas를 사용하여 World Happiness 데이터셋을 로드합니다.
file_path = 'world_happiness_2023.csv' # 이 코드 예제를 사용하는 경우 CSV 파일이 있는 경로를 의미합니다.
happiness_data = pd.read_csv(file_path, delimiter=',')
이 섹션은 필요한 라이브러리를 가져오고, Pandas를 사용하여 World Happiness 데이터셋을 로드합니다. 데이터셋은 쉼표로 구분된 파일이며, 이 코드 스니펫의 예시를 사용하는 경우 Python 파일과 동일한 디렉토리에 있어야 합니다.
2. 사용자 인터페이스(UI) 정의
이곳에서 Shiny 라이브러리를 활용하기 시작합니다. Shiny를 로드할 때 ui 라이브러리를 포함하여 웹 애플리케이션 인터페이스를 도와줍니다.
# UI 정의
app_ui = ui.page_fluid(
ui.h3("세계 행복 지수 분석"),
ui.input_select(
"year", "연도 선택:",
{str(year): str(year) for year in sorted(happiness_data['year'].unique())}
),
ui.output_ui("happiness_map")
)
app_ui 변수는 웹 애플리케이션의 레이아웃을 정의합니다. 여기에는 다음이 포함됩니다:
- 애플리케이션 제목을 나타내는 헤더 (h3).
- 사용자가 데이터셋에서 연도를 선택할 수 있는 드롭다운 메뉴 (input_select).
- 코로플레스 맵을 위한 자리 표시자 (output_ui).
3. 서버 로직 정의하기
인터페이스를 배치한 후에 서버 코드를 설정할 수 있어요:
# 서버 로직 정의하기
def server(input, output, session):
@reactive.Calc
def filtered_data():
return happiness_data[happiness_data['year'] == int(input.year())]
서버 함수는 애플리케이션의 로직을 정의합니다. 선택한 연도를 기반으로 데이터셋을 필터링하는 반응형 계산(filtered_data)이 포함되어 있어요.
4. Choropleth 지도 코딩하기 (Plotly를 사용하여, 얜!)
위 코드 세그먼트의 중심은 Plotly Express (px)를 사용하여 코로플레스 지도를 렌더링하는 happiness_map() 함수입니다:
@output
@render.ui
def happiness_map():
data = filtered_data()
fig = px.choropleth(
data,
locations='Country name', # 위치에 국가 이름 사용
locationmode='country names', # 국가 이름 사용을 지정
color='Life Ladder', # 'Life Ladder' 값에 따라 색상 지정
hover_name='Country name', # 가리킬 때 'Country name' 표시
color_continuous_scale=px.colors.sequential.YlGnBu,
labels={'Life Ladder': 'Life Ladder Score'},
title=f'{input.year()}의 세계 행복 지도'
)
fig.update_layout(height=600, margin={"r":0,"t":40,"l":0,"b":0})
fig_html = fig.to_html(full_html=False)
return ui.HTML(fig_html)
여기서 전달된 주요 속성(매개변수로 전달됨)은 다음과 같습니다:
- locations: 위치에 국가 이름 사용.
- locationmode: 국가 이름 사용을 지정.
- color:
Life Ladder값에 따라 지도에 색상을 입힘. - hover_name: 호버 시 국가 이름 표시.
- color_continuous_scale:
YlGnBu색상 척도 사용.
맵이 지정된 높이와 여백 내에 맞도록 업데이트되었습니다 (update_layout() 함수를 사용하여).
5. 앱 생성 및 실행
이 세그먼트에서 Shiny 애플리케이션을 초기화하고 실행합니다:
# 앱 생성
app = App(app_ui, server)
if __name__ == '__main__':
app.run()
UI와 서버 컴포넌트를 결합하여 애플리케이션을 기능적이고 웹 브라우저에 표시할 준비가 된 상태로 만듭니다.
여기서 필요한 모든 코드입니다! 애플리케이션을 실행하려면 Jupyter 노트북을 사용하거나 저처럼 PyCharm을 사용할 수 있습니다. 오늘까지 Shiny에 대한 경험이 매우 적었지만 PyCharm에서 실행하는 단계는 매우 직관적이었습니다.
먼저, Preferences/Project/Python Interpreter에서 라이브러리를 설치했습니다:
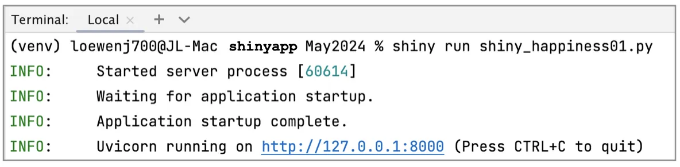
설치가 완료되면 내장된 Pycharm 터미널 창(View/Tool Windows/Terminal)에서 파이썬 파일을 Shiny 애플리케이션으로 실행할 수 있었습니다:
그리고 기본 브라우저에 표시된 매우 멋진 시각적인 결과:
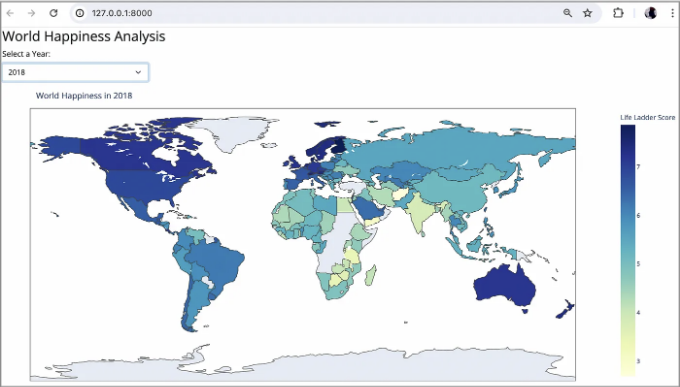
정말 멋지네요. 사용자는 드롭다운 메뉴에서 연도를 선택할 수 있고(2005-2023), 해당 연도에 맞게 지도가 자동으로 업데이트됩니다.
잘 했어요! 이제 이것을 작동시켰기를 바랍니다. 문제가 있거나 어려움이 있으면 댓글을 남겨주세요.
잘 했어요!
종합적으로...
파이썬 Shiny는 데이터 과학자들에게 유용한 데이터 시각화 도구 목록에서 빈칸을 메우고 있습니다. 이 도구는 상호작용적이고 동적인 데이터 시각화를 쉽게 만들 수 있게 해줍니다.
Shiny는 Plotly 데이터 시각화를 쉽게 렌더링할 수 있는 기능을 가지고 있어서 매력적입니다.
Shiny의 큰 장점 중 하나는 다른 유사하고 매우 인기 있는 프레임워크 Streamlit보다 더 효율적이라는 것입니다. Shiny는 코드 중 업데이트가 필요한 부분만 다시 실행하도록 설계되어 있습니다. 반면 Streamlit은 사용자가 입력할 때 애플리케이션 스크립트 전체를 렌더링합니다.
반면에, Streamlit은 경험이 적은 UI 개발자들이 빠르게 익힐 수 있습니다. 동일한 애플리케이션을 Streamlit과 Shiny 두 가지로 만들었을 때, Streamlit 앱은 30줄의 코드이고 Shiny 앱은 50줄의 코드입니다.
시각적 결과가요? 거의 동일해요.
읽어 주셔서 감사합니다.
이 유형의 이야기가 멋지시면서 글쓰기를 지원하고 싶으시다면, 제 Substack에 구독해주세요.
Substack에서는 다른 플랫폼에서 찾을 수 없는 매주 뉴스레터와 기사를 발행하고 있습니다.