
시계열 예측 분야는 계속해서 발전하고 있으며, 많은 모델들이 제안되고 최신 성능을 보여주고 있습니다.
딥러닝 모델은 특히 많은 특징을 가진 대규모 데이터셋에서 시계열 예측에 대한 일반적인 방법으로 사용되고 있습니다.
최근 몇 년간 iTransformer, SOFTS, TimesNet과 같은 다양한 모델이 제안되었지만, 그들의 성능은 종종 NHITS, PatchTST, TSMixer와 같은 모델을 기준으로 다소 부족한 경우가 있습니다.
2024년 5월에 새로운 모델이 제안되었습니다: TimeMixer. 원본 논문에 따르면 TimeMixer: 시계열 예측을 위한 분해 가능한 멀티스케일 믹싱은 특징들의 믹싱과 시리즈 분해를 MLP 기반 아키텍처에서 사용하여 예측을 생성합니다.
본문에서는 짧은 기간 및 긴 기간 예측 작업에서 우리만의 작은 벤치마크를 실행하기 전에 TimeMixer의 내부 작동 방식을 먼저 탐구합니다.
항상 원래의 연구 논문을 더 자세히 읽도록 하세요.
자, 시작해봅시다!
Discover TimeMixer
TimeMixer의 동기는 시계열 데이터가 서로 다른 규모에서 다른 정보를 담고 있다는 깨달음에서 나왔어요.
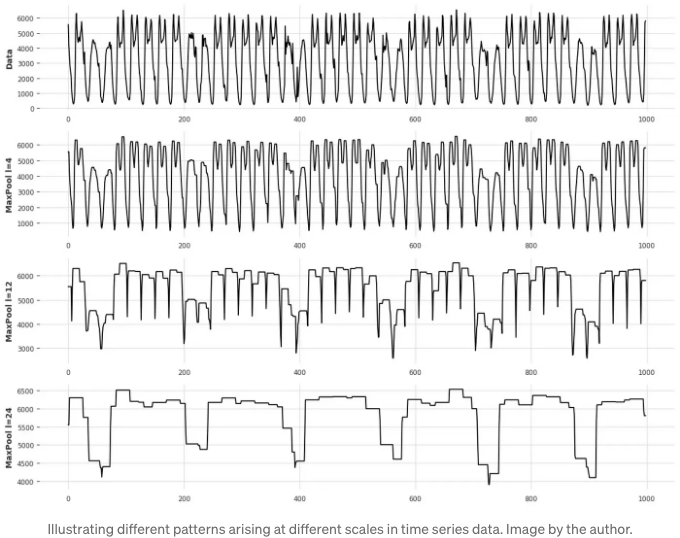
위 그림에서 우리는 데이터를 샘플링하는 규모에 따라 다른 패턴이 나타난다는 것을 볼 수 있어요.
물론, 소 샘플링 규모에서는 (그림 상단), 섬세한 변화가 있지만, 대 샘플링 규모에서 (그림 하단에 표시된대로) 더 오랜 기간 동안 시리즈에 대한 거친 변화를 볼 수 있습니다.
따라서 TimeMixer는 미시적 및 거시적 정보를 분리하고 특징 믹싱을 적용하여 TSMixer에서 완전히 탐색된 아이디어를 따릅니다.
TimeMixer의 구조
아래에서 TimeMixer의 일반적인 구조를 볼 수 있습니다.
위의 그림에서는 입력 시리즈가 먼저 평균 풀링을 사용하여 다운샘플링된 것을 볼 수 있습니다. 이렇게 함으로써 시리즈의 미세한 부분과 굵은 부분을 분리할 수 있습니다.
분리된 시리즈는 그 다음 과거 분해 가능 혼합 블록 또는 PDM 블록으로 보내져 다양한 규모의 정보가 모델에 의해 학습됩니다. 또한 추세와 계절성이 별도로 처리되는 추가적인 분해가 있음을 주목해 주세요.
마지막으로, 모델은 미래 다중 예측기 혼합 블록 또는 FMM 블록으로 전송됩니다. 이 블록은 각 규모에서 예측을 앙상블하여 최종 예측을 얻습니다.
물론, 각 단계에 대해 더 자세히 배울 정보가 많이 있기 때문에 더 자세히 다루도록 하겠습니다.
지난 가분해 혼합 (PDM)
각기 다른 척도에서 시리즈를 평균 풀링하는 첫 번째 단계는 직접 Past-Decomposable-Mixing 블록으로 넘어가기 충분히 간단합니다.
여기서 시리즈는 더 나아가 추세와 계절성 요소로 분해됩니다. 계절성 구성요소는 단기적이고 주기적인 변화를 나타내고, 추세 구성요소는 장기적인 시간 동안 천천히 변하는 것을 나타냅니다.
위 그림에서 볼 수 있듯이 상담 시리즈는 다운샘플링되었지만 여전히 추세와 계절성 특성을 보입니다. 따라서 두 구성 요소를 분리하는 것이 유익합니다. 각각 다른 정보를 담고 있기 때문이죠.
이 분해를 수행하기 위해 연구자들은 Autoformer에서 로직을 재활용했습니다. 이것은 주기적 변동을 완화하기 위해 평균 풀링을 사용하고 이로써 추세를 강조하는 것입니다.
그런 다음 입력 시리즈를 주파수와 진폭의 함수로 변환하는 푸리에 변환과 결합됩니다.
위의 이미지를 보면, 푸리에 변환은 진폭과 주파수의 함수로 나타납니다. 진폭이 가장 큰 주파수가 가장 중요하며, 이는 강한 계절적 영향을 나타냅니다.
계절적 혼합
추세 및 계절성 구성 요소가 분리되면 둘 다 혼합되게 됩니다.
계절적인 혼합의 경우, 더 큰 계절적 기간을 더 작은 계절적 기간의 집합으로 볼 수 있다는 것을 알 수 있습니다.
예를 들어, 일일 계절성에 따른 주간 계절성이 지난 일곱 일 동안 관찰될 수 있습니다.
따라서 TimeMixer는 계절적인 혼합에 대해 하향식 접근법을 사용합니다.
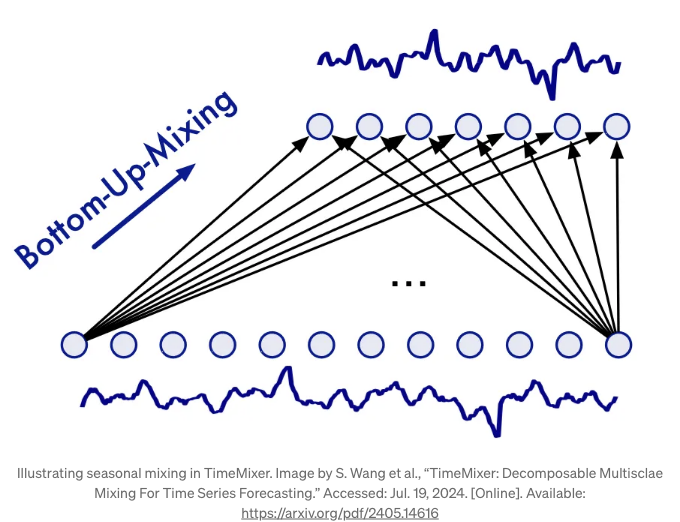
위 그림에서 계절적 혼합을 볼 수 있습니다. 계절적 혼합에서는 세부 스케일 시리즈에서 다운샘플된 시리즈까지의 정보를 통합합니다.
추세 혼합
반면에 추세 혼합에서는 TimeMixer가 아래 그림에 나와 있는 것처럼 탑-다운 접근 방식을 사용합니다.
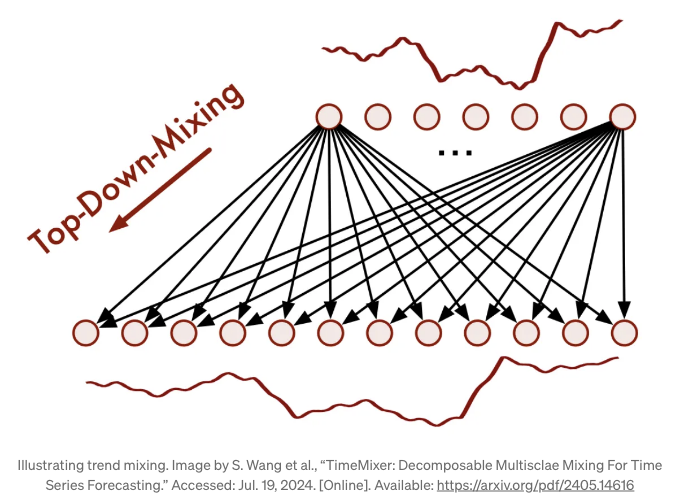
상향식 접근 방식은 트렌드 구성 요소에 사용됩니다. 왜냐하면 다운샘플링된 시리즈의 거대한 트렌드를 캡처하려고 할 때 미세한 스케일 시리즈의 잡음이 도입될 수 있기 때문입니다.
따라서 이 경우, 거대한 트렌드는 미세한 트렌드를 추가로 제공하는 데 사용됩니다.
이것이 TimeMixer가 트렌드와 계절성 구성 요소에 대한 서로 다른 스케일에서 혼합을 달성하는 방법입니다.
이 단계가 완료되면 데이터가 Future-Multipredictor-Mixing 블록으로 흐릅니다.
미래 다중예측기 혼합 (FMM)
여기서 미래 다중예측기 혼합 블록은 서로 다른 스케일에서 정보를 받습니다. 따라서, 이 정보를 집계하여 최종 예측을 출력하는 역할을 합니다.
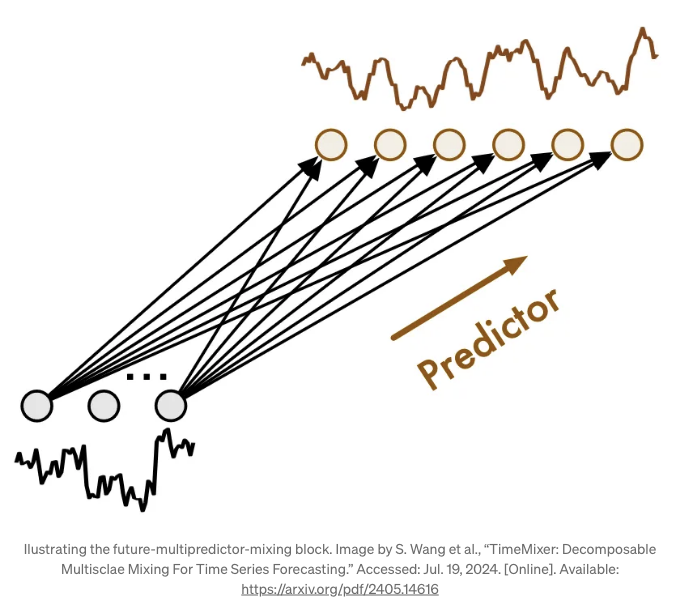
위 그림에서는 FMM 블록이 어떻게 생겼는지 볼 수 있습니다. 기본적으로 각 예측기가 다른 스케일에서 실행되기 때문에 동시에 모두 사용되지 않습니다.
예를 들어, 더 세밀한 스케일에서의 예측기는 많은 단계에서 예측에 영향을 미칠 것입니다. 반면에 거친 스케일에서의 예측기는 다운샘플된 데이터를 다루기 때문에 예측에 적은 시간 단계에서 영향을 미칠 것입니다.
이제 TimeMixer에 대한 심층적인 이해와 작동 방식을 얻었으니, Python을 사용하여 작은 벤치마크에서 적용해 봅시다.
TimeMixer를 사용한 예측
이제 TimeMixer를 사용하여 단기 및 장기적인 예측 작업을 평가해 보겠습니다.
짧은 시계 벤치마크에서는 크리에이티브 커먼즈 라이선스 하에 공개된 M3 데이터셋을 사용합니다. 이 데이터셋은 연간, 분기별, 월별로 다양한 도메인(인구통계, 금융 등)에서 수집된 데이터를 포함하고 있습니다.
장기 시계벤치마크에는 중국 한 지방의 전기 변압기에서 나오는 오일 온도를 추적하는 Electricity Transformer 데이터셋(ETT)을 사용합니다. 이 데이터셋도 크리에이티브 커먼즈 라이선스 하에 공개되어 있습니다. 한 지방의 두 지역으로부터 수집된 전기 변압기의 오일 온도를 추적하며, 각 지역에 대해 1시간마다 및 15분마다 샘플링된 데이터셋이 있습니다. 우리는 15분 간격으로 샘플링된 두 가지 데이터셋만 사용합니다.
또한, 'neuralforecast' 라이브러리를 확장하여 해당 공식 저장소에서 TimeMixer 모델의 적응된 구현을 추가하였습니다. 이를 통해 다양한 예측 모델을 사용하고 테스트하는 간소화된 경험을 제공합니다.
이 글을 작성하는 시점에, TimeMixer는 'neuralforecast'의 안정 버전에 아직 포함되지 않았음을 유념해 주세요.
결과를 재현하기 위해 저장소를 복제하고 해당 브랜치에서 작업해야 할 수도 있어요.
브랜치가 병합되면 다음을 실행할 수 있어요:
pip install git+https://github.com/Nixtla/neuralforecast.git
언제나처럼, 이 실험에 대한 코드는 GitHub에서 확인할 수 있어요.
시작해봅시다!
짧은 단기 예측
먼저 필요한 패키지를 가져와봅시다. 이 패키지들은 두 벤치마크에 모두 사용될 것입니다. neuralforecast가 예상하는 형식으로 데이터셋을 로드하기 위해 datasetsforecast 라이브러리를 사용하고 있음에 주목해주세요.
import time
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from datasetsforecast.m3 import M3
from datasetsforecast.long_horizon import LongHorizon
from neuralforecast.core import NeuralForecast
from neuralforecast.losses.pytorch import MAE, MSE
from neuralforecast.models import TimeMixer, PatchTST, iTransformer, NHITS, NBEATS
from utilsforecast.losses import mae, mse, smape
from utilsforecast.evaluation import evaluate
그럼 데이터셋을 불러오고 적절한 빈도와 수평을 가진 함수를 정의해 봅시다.
def get_dataset(name):
if name == 'M3-yearly':
Y_df, *_ = M3.load("./data", "Yearly")
horizon = 6
freq = 'Y'
elif name == 'M3-quarterly':
Y_df, *_ = M3.load("./data", "Quarterly")
horizon = 8
freq = 'Q'
elif name == 'M3-monthly':
Y_df, *_ = M3.load("./data", "Monthly")
horizon = 18
freq = 'M'
return Y_df, horizon, freq
코드가 준비되었으니, 이제 모델을 초기화하고 벤치마크를 실행할 수 있습니다.
여기서, 우리는 이런 종류의 작업에서 알려진 빠르고 정확한 NHITS와 NBEATS 모델에 TimeMixer를 비교해봅니다.
이 실험을 실행하려면, 우리는 먼저 결과를 저장할 빈 리스트를 초기화하고 각 데이터셋에 대해 for 루프를 시작합니다. 데이터셋을 로드한 후에는 학습 세트와 테스트 세트로 분할합니다.
results = []
DATASETS = ['M3-yearly', 'M3-quarterly', 'M3-monthly']
for dataset in DATASETS:
Y_df, horizon, freq = get_dataset(dataset)
test_df = Y_df.groupby('unique_id').tail(horizon)
train_df = Y_df.drop(test_df.index).reset_index(drop=True)
같은 for 루프 안에서 모델을 초기화합니다. 여기서, 모든 모델에 대해 기본 매개변수를 유지합니다. 업데이트된 코드는 다음과 같습니다:
results = []
DATASETS = ['M3-yearly', 'M3-quarterly', 'M3-monthly']
for dataset in DATASETS:
Y_df, horizon, freq = get_dataset(dataset)
test_df = Y_df.groupby('unique_id').tail(horizon)
train_df = Y_df.drop(test_df.index).reset_index(drop=True)
timemixer_model = TimeMixer(input_size=2*horizon,
h=horizon,
n_series=1,
scaler_type='identity',
early_stop_patience_steps=3)
nbeats_model = NBEATS(input_size=2*horizon,
h=horizon,
scaler_type='identity',
max_steps=1000,
early_stop_patience_steps=3)
nhits_model = NHITS(input_size=2*horizon,
h=horizon,
scaler_type='identity',
max_steps=1000,
early_stop_patience_steps=3)
학습 단계 수가 최대 1000단계로 제한되어 있지만 손실이 3회의 학습 단계 동안 개선되지 않으면 학습을 중지합니다.
모델 초기화 후 학습하고 예측할 수 있습니다. 여기서는 또한 학습 프로세스를 완료하는 데 걸리는 시간을 추적합니다.
아래는 업데이트 코드 블록입니다.
results = []
DATASETS = ['M3-yearly', 'M3-quarterly', 'M3-monthly']
for dataset in DATASETS:
Y_df, horizon, freq = get_dataset(dataset)
test_df = Y_df.groupby('unique_id').tail(horizon)
train_df = Y_df.drop(test_df.index).reset_index(drop=True)
timemixer_model = TimeMixer(input_size=2*horizon,
h=horizon,
n_series=1,
scaler_type='identity',
early_stop_patience_steps=3)
nbeats_model = NBEATS(input_size=2*horizon,
h=horizon,
scaler_type='identity',
max_steps=1000,
early_stop_patience_steps=3)
nhits_model = NHITS(input_size=2*horizon,
h=horizon,
scaler_type='identity',
max_steps=1000,
early_stop_patience_steps=3)
MODELS = [timemixer_model, nbeats_model, nhits_model]
MODEL_NAMES = ['TimeMixer', 'NBEATS', 'NHITS']
for i, model in enumerate(MODELS):
nf = NeuralForecast(models=[model], freq=freq)
start = time.time()
nf.fit(train_df, val_size=horizon)
preds = nf.predict()
end = time.time()
elapsed_time = round(end - start,0)
preds = preds.reset_index()
test_df = pd.merge(test_df, preds, 'left', ['ds', 'unique_id'])
모델 평가만 남았습니다. 여기서 utilsforecast 라이브러리를 사용하여 평균 절대 오차 (MAE) 및 대칭 평균 절대 백분율 오차 (sMAPE)를 사용합니다.
전체 코드 블록은 다음과 같습니다:
results = []
DATASETS = ['M3-yearly', 'M3-quarterly', 'M3-monthly']
for dataset in DATASETS:
Y_df, horizon, freq = get_dataset(dataset)
test_df = Y_df.groupby('unique_id').tail(horizon)
train_df = Y_df.drop(test_df.index).reset_index(drop=True)
timemixer_model = TimeMixer(input_size=2*horizon,
h=horizon,
n_series=1,
scaler_type='identity',
early_stop_patience_steps=3)
nbeats_model = NBEATS(input_size=2*horizon,
h=horizon,
scaler_type='identity',
max_steps=1000,
early_stop_patience_steps=3)
nhits_model = NHITS(input_size=2*horizon,
h=horizon,
scaler_type='identity',
max_steps=1000,
early_stop_patience_steps=3)
MODELS = [timemixer_model, nbeats_model, nhits_model]
MODEL_NAMES = ['TimeMixer', 'NBEATS', 'NHITS']
for i, model in enumerate(MODELS):
nf = NeuralForecast(models=[model], freq=freq)
start = time.time()
nf.fit(train_df, val_size=horizon)
preds = nf.predict()
end = time.time()
elapsed_time = round(end - start,0)
preds = preds.reset_index()
test_df = pd.merge(test_df, preds, 'left', ['ds', 'unique_id'])
evaluation = evaluate(
test_df,
metrics=[mae, smape],
models=[f"{MODEL_NAMES[i]}"],
target_col="y",
)
evaluation = evaluation.drop(['unique_id'], axis=1).groupby('metric').mean().reset_index()
model_mae = evaluation[f"{MODEL_NAMES[i]}"][0]
model_smape = evaluation[f"{MODEL_NAMES[i]}"][1]
results.append([dataset, MODEL_NAMES[i], round(model_mae, 0), round(model_smape*100,2), elapsed_time])
results_df = pd.DataFrame(data=results, columns=['dataset', 'model', 'mae', 'smape', 'time'])
results_df.to_csv('./M3_benchmark.csv', header=True, index=False)
이 작업을 완료하면 다음과 같은 결과가 나타납니다.
위의 표에서 NHITS가 전반적으로 최고의 성능을 달성한다는 것을 확인할 수 있습니다.
또한 TimeMixer는 실행 시간이 가장 길다는 점을 분명히 알 수 있습니다. 가장 빠른 모델보다 약 7배 느리다. 더구나 NHITS와 N-BEATS와 비교했을 때 경쟁력있는 오류 메트릭을 달성하지 못하고 있습니다.
TimeMixer의 단기 예측 성능이 기대에 못 미친다는 것으로 보입니다. 그래서 좀 더 긴 시계열에 대해 테스트해보겠습니다.
장기 예측
ETT 데이터 세트에서 모델을 실행하는 설정은 비슷합니다.
다시 한번, 데이터 세트를 로드하고 검증 크기, 테스트 크기 및 주파수를 정의하는 함수를 만듭니다.
def load_data(name):
if name == 'Ettm1':
Y_df, *_ = LongHorizon.load(directory='./', group='ETTm1')
Y_df['ds'] = pd.to_datetime(Y_df['ds'])
freq = '15T'
h = 96
val_size = 11520
test_size = 11520
elif name == 'Ettm2':
Y_df, *_ = LongHorizon.load(directory='./', group='ETTm2')
Y_df['ds'] = pd.to_datetime(Y_df['ds'])
freq = '15T'
h = 96
val_size = 11520
test_size = 11520
return Y_df, h, val_size, test_size, freq
다음은 TimeMixer를 PatchTST와 iTransformer에 대해 테스트하는 것입니다. 일반적으로 이 모델들은 장기 예측에서 성능이 가장 좋습니다.
구체적으로, 96 단계의 예측 기간에 대해 테스트합니다.
이 실험에서는 각 모델의 성능을 더 견고하게 평가하기 위해 교차 검증을 실행합니다. 또한 각각의 논문에서 보고된 최적 매개변수를 사용합니다.
DATASETS = ['Ettm1', 'Ettm2']
for dataset in DATASETS:
Y_df, horizon, val_size, test_size, freq = load_data(dataset)
timemixer_model = TimeMixer(input_size=horizon,
h=horizon,
n_series=7,
e_layers=2,
d_model=16,
d_ff=32,
down_sampling_layers=3,
down_sampling_window=2,
learning_rate=0.01,
scaler_type='robust',
batch_size=16,
early_stop_patience_steps=5)
patchtst_model = PatchTST(input_size=horizon,
h=horizon,
encoder_layers=3,
n_heads=4,
hidden_size=16,
dropout=0.3,
patch_len=16,
stride=8,
scaler_type='identity',
max_steps=1000,
early_stop_patience_steps=5)
iTransformer_model = iTransformer(input_size=horizon,
h=horizon,
n_series=7,
e_layers=2,
hidden_size=128,
d_ff=128,
scaler_type='identity',
max_steps=1000,
early_stop_patience_steps=3)
models = [timemixer_model, patchtst_model, iTransformer_model]
nf = NeuralForecast(models=models, freq=freq)
nf_preds = nf.cross_validation(df=Y_df, val_size=val_size, test_size=test_size, n_windows=None)
nf_preds = nf_preds.reset_index()
evaluation = evaluate(df=nf_preds, metrics=[mae, mse], models=['TimeMixer', 'PatchTST', 'iTransformer'])
evaluation.to_csv(f'{dataset}_results.csv', index=False, header=True)
이 모델의 성능을 평가하기 위해 이러한 벤치마크에 일반적으로 사용되는 평균 절대 오차(MAE)와 평균 제곱 오차(MSE)를 사용합니다.
메트릭은 ETTm1 및 ETTm2 데이터셋의 일곱 개의 시리즈에 대한 예측에 대해 평균화되었음을 기억해 주세요.
이 실험의 결과는 아래에서 확인할 수 있습니다.
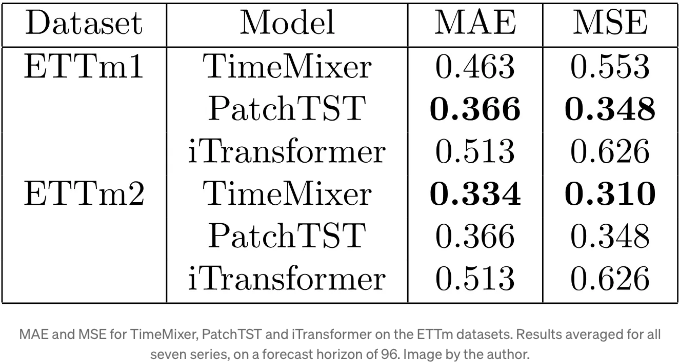
위의 표를 보면, PatchTST가 ETTm1에 대해 가장 좋은 결과를 달성하는 반면, TimeMixer는 ETTm2에서 최상의 결과를 얻습니다.
물론, 이는 철저한 벤치마킹은 아니지만, TimeMixer가 짧은 시계열보다는 긴 시계열을 예측하는 데 훨씬 뛰어나다는 것을 알아보는 것은 흥미롭습니다.
그러므로, 여러 시즌 주기를 예측하는 경우에는 TimeMixer를 테스트에 고려해야 합니다.
결론
TimeMixer는 시계열의 미시 및 매크로 변동을 캡처하기 위해 서로 다른 규모에서 특성을 혼합하는 MLP 기반 모델입니다. 이를 통해 예측을 할 수 있습니다.
우리의 소규모 벤치마크에서 우리는 TimeMixer가 짧은 주기의 예측에 적합하지 않다는 것을 알게 되었습니다. NHITS 또는 N-BEATS보다 성능이 더 우수하지 않고 후자보다 훨씬 느리기 때문입니다.
그러나 장기 주기의 예측에서 TimeMixer는 매우 좋은 결과를 얻었으며, ETTm2 데이터셋에서 iTransformer 및 PatchTST와 비교했을 때 최고의 성능을 보였습니다.
지금 이러한 벤치마크는 포괄적이지 않습니다. 모델을 Python에서 어떻게 사용하는지 배우고, 실제로 어떻게 작동하는지 확인하기 위한 것이었습니다.
언제나 각 문제는 고유한 해결책을 요구한다고 믿어요. 따라서 TimeMixer와 다른 모델을 테스트해서 여러분의 특정 시나리오에 최적의 모델을 찾아보세요.
읽어 주셔서 감사합니다! 즐겁게 읽으셨기를 바라며 무엇인가 새로운 것을 배우셨기를 바랍니다!
건배 🍻
제게 힘을주세요
제 작품을 즐기셨나요? Buy me a coffee로 나를 응원해주세요. 단순한 방법으로 나를 격려할 수 있고, 저는 커피 한 잔을 즐길 수 있어요! 만약 원하신다면 아래 버튼을 클릭해주세요 👇

참고 자료
S. Wang 등, “TimeMixer: Decomposable Multiscale Mixing For Time Series Forecasting.” 접속일: 2024년 7월 19일. [온라인]. 이용 가능: https://arxiv.org/pdf/2405.14616
TimeMixer의 원본 코드 저장소: GitHub