
개요
우리는 AI 시대에 살고 있는 행운아입니다. 인공지능 기술이 급속히 발전하여 요즘에는 더 접근하기 쉬워졌습니다. 대부분의 공개된 모델들은 다양한 범주의 충분한 양의 데이터로 잘 훈련되어 있어서 다양한 범주의 이미지를 생성할 수 있습니다.
그런데 만약 모델이 우리가 생성하고 싶은 특정한 주제를 배운 적이 없다면 어떨까요? 예를 들어, 오늘 아침 만든 케이크의 이미지를 생성하고 싶다고 합시다. 모델은 수많은 종류의 케이크 이미지를 생성할 수 있지만, 오늘 아침 만든 내 케이크 이미지를 만드는 방법을 알지 못합니다.
0부터 훈련하는 것은 개인에게는 거의 불가능하지만, 모델에 새로운 주제를 통합하는 것은 진화하는 모델 파인튜닝 기술 덕분에 매우 쉽습니다. 2022년부터 트렌드로 떠오르는 최신 세대 모델인 Stable Diffusion은 이미지 생성을 위한 새로운 시대를 열어주고 있습니다.
이 글에서는 현대 기술 LoRA를 사용하여 Stable Diffusion 모델을 파인튜닝하는 단계별 안내를 공유하고자 합니다. 이 연습은 모두가 적절한 장치를 갖추지 않고도 Kaggle 노트북에서 수행할 수 있으므로 누구나 걱정 없이 이 연습을 할 수 있습니다.
구현에 들어가기 전에, Stable Diffusion 개념과 파인튜닝 기술 LoRA에 대해 간단히 알아보겠습니다. 이미 이에 대해 알고 있다면 구현 섹션으로 건너뛸 수 있습니다.
Stable Diffusion

안녕하세요! Stable Diffusion은 텍스트와 이미지에서 사실적인 이미지를 생성할 수 있는 생성적 AI 모델입니다. 확산 모델은 이미지 공간이 아닌 잠재 공간에서 마법을 부리기 때문에 낮은 계산 능력이 필요하다는 특징으로 이미지 생성이 대중에게 접근 가능해졌습니다. 누구나 CPU 머신을 이용하여 커피 시간 동안 존재하지 않는 이미지를 생성할 수 있습니다.
HuggingFace¹와 Stable Diffusion Online²과 같은 많은 온라인 Stable Diffusion 플랫폼이 일반 대중과 개발자들을 위해 있습니다. 기계 학습 지식 없이 이미지를 생성할 수 있습니다.
LoRA (Low Rank Adaption)

LoRA는 Stable Diffusion 네트워크의 교차 주의 레이어에 추가 가중치를 부여하는 세밀 조정 방법입니다. 교차 주의 레이어는 도표 2의 노란 블록으로 표시됩니다. 교차 주의 레이어는 이미지 Z^T와 텍스트 τ^θ의 중간 정보를 융합시킵니다. 교차 주의 레이어에 가중치를 추가하면 텍스트 프롬프트와 이미지의 상관 관계를 확장시킵니다. 이것이 LoRA가 Stable Diffusion 모델에 새로운 지식을 도입하는 방식입니다.
수정된 가중치는 더 작은(저랭크) 행렬로 분해됩니다. 작은 행렬은 더 적은 매개변수를 가지고 별도로 저장됩니다. 이것이 LoRA 가중치 파일이 처리 가능한 크기로 유지되지만 기본 Stable Diffusion 모델과 함께 사용되어야 하는 이유입니다.
LoRA의 가중치 크기는 일반적으로 2~200MB 사이입니다. 모델을 공유하고 관리하는 장점입니다. 몇 기가바이트 단위로 전체 모델을 공유하는 대신, LoRA 가중치를 훨씬 작은 크기로 공유함으로써 더 효율적입니다.
환경
이 연습은 다음 환경으로 구성된 Kaggle 노트북에서 실행됩니다:
- NVIDIA Tesla P100 (RAM=16G)
- diffusers-0.30.0.dev0
- Pytorch 2.1.2
- Python 3.10
Kaggle 노트북에는 Python과 PyTorch가 설치되어 있습니다. 우리가 설치해야 할 유일한 라이브러리는 HuggingFace의 Diffusers입니다.
아래 명령어를 사용하여 소스로부터 Diffusers를 설치할 수 있습니다. 소스로부터 설치하는 것은 라이브러리의 최신 버전을 보장합니다. 경로 /kaggle/working은 Kaggle 런타임의 기본 작업 공간입니다. 개발 환경에 맞게 경로를 조정할 수 있습니다.
%cd /kaggle/working/ !pip install accelerate !git clone https://github.com/huggingface/diffusers %cd /kaggle/working/diffusers !pip install /kaggle/working/diffusers/. -q %cd /kaggle/working/diffusers/examples/text_to_image !pip install -r /kaggle/working/diffusers/examples/text_to_image/requirements.txt -q !pip install --upgrade peft transformers xformers bitsandbytes -q
더 많은 설치 가이드라인은 공식 웹사이트에서 확인할 수 있습니다.
실험
이 연습에서는 모델에 크레용 신짱 피규린을 소개하고자 합니다. 아래 섹션에서는 다음 단계를 진행해 보겠습니다.
단계 1: 데이터 수집

우선, 주제의 몇 장의 이미지를 수집해야 합니다. 이 연습에서는 크레용 신짱 피규린의 사진 25장을 수집하여 훈련 데이터로 사용합니다. 데이터 수집을 위해 권장하는 조언은 아래와 같습니다:
- 이미지 크기를 표준화하세요: 예를 들어, 512x512 크기로.
- 고품질 이미지: 사진은 12M 해상도로 촬영되어야 합니다.
- 주제를 이미지 중앙에 유지하세요.
또한, 모델이 캐릭터의 눈, 헤어스타일, 체형과 같은 일반적인 특징을 학습하도록 훈련 세트에서 가능한 다양한 요소를 다루는 것이 중요합니다. 다시 말해, 우리는 모델이 특정한 의상 스타일(예: 빨간 티셔츠와 노란 반바지)이나 자세(예: 서 있음)이 아니라 크레용신짱 피규린임을 학습하길 원합니다.
훈련 크기가 5, 15, 25인 실험을 진행했습니다. 각 라운드 간 이미지 차이는 10개뿐이지만, 모델의 일반화 정도가 크게 향상되었습니다.
단계 2: 기준 평가
from diffusers import AutoPipelineForText2Image
pipeline = AutoPipelineForText2Image.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16).to("cuda")
prompt = "크레용신짱 피규어."
image = pipeline(prompt, num_inference_steps=100).images[0]
image.save("baseline.png")
팔을 걷어올리고 훈련을 시작하기 전에, 상기한 파이썬 스크립트를 사용하여 파인튜닝하려는 구체적인 피규어를 사전 훈련된 모델이 이미 알고 있는지 확인하고 싶습니다.
- AutoPipelineForText2Image 클래스를 사용하여 사전 훈련된 Stable Diffusion 모델 stable-diffusion-v1–5을 로드합니다.
- 그런 다음 텍스트 프롬프트를 "크레용신짱 피규어."로 설정합니다. 텍스트 정보가 모델에게 직관적으로 전달되도록 텍스트 프롬프트를 간결하게 유지합니다.
- 텍스트 프롬프트와 추론 횟수를 AutoPipelineForText2Image의 인스턴스에 전달하고 생성 프로세스를 수행합니다.

이 스크립트는 여러 번 실행되며 생성된 이미지 중 세 개가 그림 4에 표시됩니다. 결과는 미리 훈련된 모델이 인물 캐릭터의 작은 모형 일 수 있지만 '크레용신짱'이라는 접두어가 정확히 어떤 캐릭터를 가리키는지는 알지 못한다는 것을 보여줍니다. 생성된 이미지에서 보이는 제한은 보이지 않는 주제로 모델을 세세하게 조정하는 것이 이니셔티브임을 타당하게 검증합니다.
단계 3: 세세한 조정

새로운 식별자 정의
훈련용 이미지 몇 장을 수집하는 것 외에도 주제에 대한 새로운 이름을 선택해야 합니다. 텍스트 프롬프트 안에 새 이름이 표시될 때마다 수정된 모델이 새 주제를 가리킨다는 것을 이해하고 이에 맞게 콘텐츠를 생성합니다.
왜 새 이름이 필요한가요? 원래 이름인 크레용신짱이 더 대표적이지 않나요? 이것의 아이디어는 이미 훈련된 기존 이름들과 혼동되지 않는 고유한 이름이 필요하다는 것입니다. 저희 경우에는 그림 그리는 데 사용한 크레용을 암시하는 '크레용'이라는 말이 포함되어 있습니다. 생성된 이미지에는 연관된 텍스트 프롬프트가 크레용신짱을 포함하고 있다면 크레용 관련 콘텐츠가 포함될 수 있습니다.
새 식별자로 무작위 이름을 사용하는 것이 좋습니다. 저는 이 연습에 대해 aawxbc라는 이름을 선택했는데, 거의 기존 이름과 겹치지 않습니다. 다른 독특한 이름을 사용할 수도 있습니다.

캐글 노트북에서 작업 공간(/kaggle/working/) 이외에도 일반적으로 사용되는 다른 디렉토리는 /kaggle/input/ 입니다. 여기에는 체크포인트 및 훈련 이미지와 같은 작업에 필요한 입력을 저장합니다. 아래는 train_dreambooth_lora.py 스크립트를 기반으로 한 완전한 훈련 명령입니다.
!accelerate config default
!mkdir /kaggle/working/figurine
!accelerate launch --mixed_precision="fp16" /kaggle/working/diffusers/examples/dreambooth/train_dreambooth_lora.py \
--mixed_precision="fp16" \
--pretrained_model_name_or_path="runwayml/stable-diffusion-v1-5" \
--instance_data_dir="/kaggle/input/aawxbc" \
--instance_prompt="a photo of aawxbc figurine" \
--class_data_dir="/kaggle/working/figurine" \
--class_prompt="a photo of figurine" \
--with_prior_preservation \
--prior_loss_weight=1.0 \
--use_8bit_adam \
--lr_scheduler="constant" \
--gradient_checkpointing \
--enable_xformers_memory_efficient_attention \
--num_train_epochs=50 \
--output_dir="/kaggle/working/dreambooth-lora"
일부 주요 설정을 살펴보겠습니다:
- mixed_precision [optional]: 플랫폼에서 지원하는 정밀도를 선택하세요. 옵션은 fp32, fp16 및 bf16이 있습니다.
- class_prompt [optional]: 클래스 데이터를 저장하는 프롬프트와 폴더입니다. 이 실험에서는 새로운 유형의 피규린을 학습하기를 원하기 때문에 클래스 이름은 figurine입니다.
- class_data_dir [optional]: 모델에서 생성된 클래스 이미지를 저장하는 디렉토리입니다. 이 경우 모델은 일반 피규린 이미지를 생성하고 해당 디렉토리에 저장합니다.
- instance_prompt [mandatory]: 새로운 주제에 대한 텍스트 프롬프트를 정의합니다. 형식은 '새로운 이름' '클래스 이름'과 같이 지정됩니다. 예시로 aawxbc figurine, uvhhhl cat 등이 있습니다.
- instance_data_dir [mandatory]: 학습 샘플을 저장하는 디렉토리입니다. 이 연습에서는 이 디렉토리에 이전에 언급된 25개의 샘플을 업로드합니다.
- num_train_epochs [optional]: 훈련할 에폭의 수입니다.
위 단계를 따라 데이터 수집, 라이브러리 설치, 및 훈련을 완료하면 이제 output_dir로 정의된 디렉토리에 저장된 LoRA 가중치 pytorch_lora_weights.safetensors를 찾을 수 있습니다. 가중치 파일의 크기는 3.2 MB로 다루기 쉽습니다.
단계 4: 추론 — 새 이미지 생성
from diffusers import AutoPipelineForText2Image
pipeline = AutoPipelineForText2Image.from_pretrained("runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16).to("cuda")
pipeline.load_lora_weights("/kaggle/working/dreambooth-lora", weight_name="pytorch_lora_weights.safetensors")
prompt = "aawxbc 피규린의 사진."
image = pipeline(prompt, num_inference_steps=180).images[0]
image.save("aawxbc.png")
로라 가중치를 성공적으로 내보낸 후, 마지막이자 가장 흥미로운 부분으로 넘어갈 수 있습니다: 새 이미지 생성하기. 로라 가중치는 독립적으로 작동하지 않기 때문에 원본 stable diffusion과 로라 가중치 파일 모두를 불러와야 합니다.
Python 스크립트에서는 기준 평가에 사용한 단계들 위에, 추가적인 단계로 LoRA 모델을 불러오는 과정이 있습니다. 함수 .load_lora_weights()를 사용하여 디렉토리와 로라 가중치 파일의 이름을 전달하면 됩니다.

텍스트 프롬프트에는 스크립트에 표시된대로 클래스 이름이 figurine이며 식별자 aawxbc가 포함됩니다. 대응하는 텍스트 프롬프트로 생성된 이미지 두 세트가 도 7과 도 8에 설명되어 있습니다. 세밀 조정 후 모델이 크레용 신짱 피규어를 생성할 수 있는 것을 확인할 수 있습니다.

새로운 모델을 추가로 교차 검증할 수 있습니다. LoRA 가중치를 로드하는 줄을 주석 처리하고 텍스트 프롬프트를 그대로 유지하면 됩니다. 원본 안정된 확산 모델은 식별자 aawxbc를 제대로 해석하지 못하는 것을 볼 수 있습니다. 이는 기준 평가와 일치하며 LoRA 모델이 기여하는 새로운 기능을 강조합니다.
요약
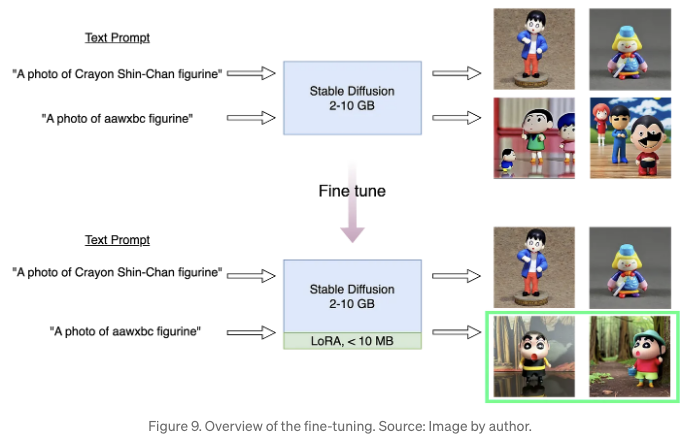
작업 개요는 이미지 9에 설명되어 있습니다. 새로운 모델은 LoRA 가중치를 결합하여, 초록색 사각형으로 강조된 새로운 인스턴스 이름인 aawxbc로 크레용신짱 모형의 이미지를 생성할 수 있습니다.
전체 파인튜닝이 간단하다는 것을 느낄 수 있을 것입니다. 우리가 해야 할 일은 충분한 수의 이미지를 수집하고, 새로운 주제를 존재하지 않는 식별자로 지정하는 것 뿐입니다. 이것으로 끝입니다. 모든 어려운 작업은 코드에서 처리됩니다.
항상 읽어 주셔서 감사합니다. 이 글이 도움이 되었으면 좋겠습니다. 어떠한 피드백도 환영하며 감사히 받겠습니다.
참고문헌
[1] https://huggingface.co/spaces/stabilityai/stable-diffusion [2] https://stablediffusionweb.com/