Microsoft GraphRAG 결과를 Neo4j에 저장하고 LangChain 또는 LlamaIndex로 로컬 및 글로벌 retrievers를 구현하세요!

최근 Microsoft의 GraphRAG 구현은 상당한 관심을 받고 있습니다. 지난 블로그 글에서는 그래프 구성 방법과 연구 논문에서 강조된 몇 가지 혁신적인 측면을 탐구했습니다. 간단히 말하면, GraphRAG 라이브러리에 대한 입력은 다양한 정보를 포함하는 소스 문서들입니다. 이러한 문서들은 Large Language Model (LLM)을 사용하여 처리되어 문서에 나타나는 엔티티에 대한 구조화된 정보가 추출됩니다. 이 추출된 구조화된 정보는 지식 그래프를 구성하는 데 사용됩니다.
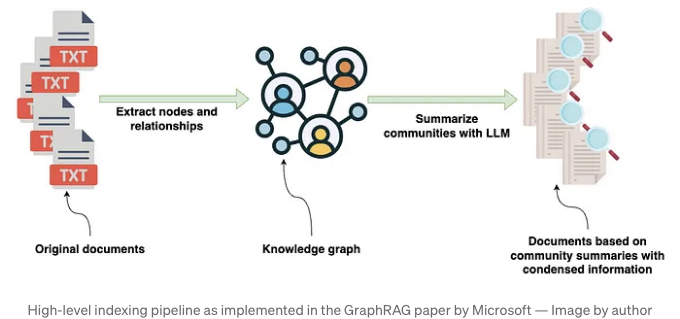
지식 그래프가 구축된 후, GraphRAG 라이브러리는 그래프 알고리즘의 조합을 사용합니다. 구체적으로 Leiden 커뮤니티 탐지 알고리즘 및 LLM 프롬프팅을 사용하여 지식 그래프에서 발견된 엔티티 및 관계의 커뮤니티에 대한 자연어 요약을 생성합니다.
이 포스트에서는 GraphRAG 라이브러리에서의 출력을 가져와 Neo4j에 저장한 후, LangChain과 LlamaIndex Orchestration 프레임워크를 사용하여 직접 Neo4j에서 리트리버를 설정하는 방법을 살펴보겠습니다.
코드와 GraphRAG 출력은 GitHub에서 확인할 수 있으며, GraphRAG 추출 프로세스를 건너뛸 수 있습니다.
데이터셋
이 블로그 글에 특징 있는 데이터셋은 Charles Dickens의 "크리스마스 캐롤"입니다. 이 데이터는 Gutenberg Project를 통해 무료로 이용할 수 있습니다.
우리는 소개 문서에서 강조된 이 책을 소스 문서로 선택했기 때문에 추출 작업을 쉽게 수행할 수 있었습니다.
그래프 구축
그래프 추출 부분을 건너뛸 수 있지만, 가장 중요한 몇 가지 구성 옵션에 대해 이야기하려 합니다. 예를 들어, 그래프 추출은 토큰 집약적이고 비용이 많이 들 수 있습니다. 그렇기 때문에 상대적으로 저렴하지만 성능이 우수한 gpt-4o-mini와 같은 LLM으로 추출을 테스트하는 것이 유용할 것입니다. gpt-4-turbo로부터의 비용 절감은 이 블로그 글에서 설명된대로 충분히 크며, 좋은 정확도를 유지할 수 있습니다.
GRAPHRAG_LLM_MODEL=gpt-4o-mini
가장 중요한 설정은 추출하려는 엔터티의 유형입니다. 기본적으로 조직, 사람, 이벤트 및 지리가 추출됩니다.
GRAPHRAG_ENTITY_EXTRACTION_ENTITY_TYPES=organization,person,event,geo
이러한 기본 엔터티 유형은 책에 대해 잘 작동할 수 있지만, 특정 사용 사례를 위해 처리하려는 문서의 도메인에 따라 이를 적절히 변경해야 합니다.
또 다른 중요한 설정은 최대 정보 추출 값입니다. 저자들은 발견했고, 우리도 따로 검증했는데, LLM은 한 번의 추출로 모든 가능한 정보를 추출하지 않는다는 것입니다.
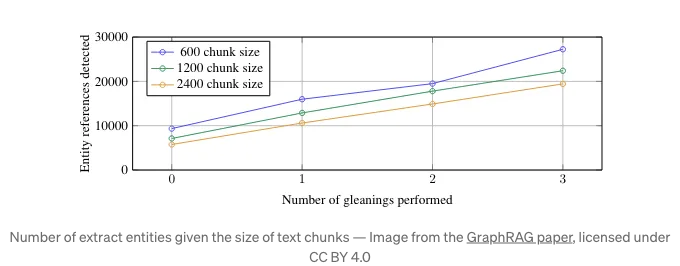
정보 추출 구성은 LLM이 여러 번의 추출을 수행할 수 있게 합니다. 위 이미지에서 여러 번의 추출(정보 추출)을 실시할 때 더 많은 정보를 추출함을 명확히 알 수 있습니다. 여러 번의 추출은 토큰이 많이 필요하므로, 비용을 낮추기 위해 gpt-4o-mini와 같이 더 저렴한 모델을 사용하는 것이 도움이 됩니다.
GRAPHRAG_ENTITY_EXTRACTION_MAX_GLEANINGS=1
또한 클레임이나 공변량 정보는 기본적으로 추출되지 않습니다. GRAPHRAG_CLAIM_EXTRACTION_ENABLED 구성을 설정하여 활성화할 수 있습니다.
GRAPHRAG_CLAIM_EXTRACTION_ENABLED=False
GRAPHRAG_CLAIM_EXTRACTION_MAX_GLEANINGS=1
단일 통과로 모든 구조화된 정보를 추출하는 것이 아니라는 것이 반복 주제인 것 같습니다. 따라서 여기에는 글리닝 구성 옵션이 있습니다.
아직 자세히 살펴보지 못했지만 흥미로운 점은 프롬프트 튜닝 섹션입니다. 프롬프트 튜닝은 선택 사항이지만 정확도를 향상시킬 수 있기 때문에 권장됩니다.
설정이 완료되면 그래프 추출 파이프라인을 실행하는 방법을 따를 수 있습니다. 이 파이프라인은 다음 단계로 구성되어 있습니다.
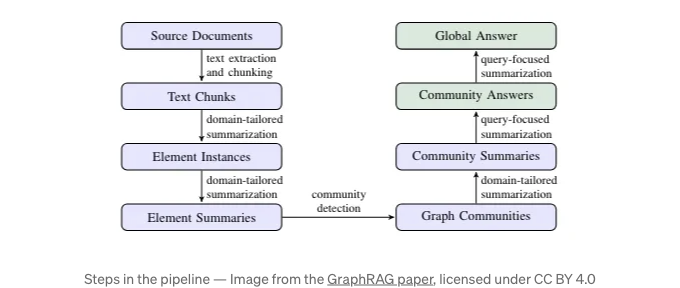
그 추출 파이프라인은 위 이미지에서 파란색 단계를 실행합니다. 그래프 구성 및 커뮤니티 요약에 대해 자세히 알아보려면 이전 블로그 포스트를 확인해주세요. MSFT GraphRAG 라이브러리의 그래프 추출 파이프라인의 출력은 Operation Dulce 예시에서 보이는 일련의 Parquet 파일입니다.
이러한 Parquet 파일은 Neo4j 그래프 데이터베이스로 쉽게 가져와서 하류 분석, 시각화 및 검색에 활용할 수 있습니다. 무료 클라우드 Aura 인스턴스를 사용하거나 로컬 Neo4j 환경을 설정할 수 있습니다. 제 친구 Michael Hunger가 Parquet 파일을 Neo4j로 가져오는 작업의 대부분을 수행했습니다. 이 블로그 포스트에서는 가져오기 설명을 건너뜁니다. 하지만 가져오기 작업은 다섯 개 또는 여섯 개의 CSV 파일로부터 지식 그래프를 가져오고 구성하는 것으로 이루어져 있습니다. CSV 가져오기에 대해 더 알고 싶다면 Neo4j Graph Academy 강좌를 확인해보세요.
Jupyter 노트북에 대한 가져오기 코드와 예시 GraphRAG 출력은 GitHub에서 이용할 수 있습니다.
가져오기가 완료되면 Neo4j Browser를 열어 가져온 그래프의 일부를 유효화하고 시각화할 수 있습니다.
그래프 분석
리트리버 구현으로 넘어가기 전에 추출된 데이터에 친숙해지기 위해 간단한 그래프 분석을 수행할 것입니다. 우리는 데이터베이스 연결을 정의하고 Cypher 문(그래프 데이터베이스 쿼리 언어)를 실행하고 Pandas DataFrame을 출력하는 함수를 작성할 것입니다.
NEO4J_URI="bolt://localhost"
NEO4J_USERNAME="neo4j"
NEO4J_PASSWORD="password"
driver = GraphDatabase.driver(NEO4J_URI, auth=(NEO4J_USERNAME, NEO4J_PASSWORD))
def db_query(cypher: str, params: Dict[str, Any] = {}) -> pd.DataFrame:
"""Cypher 문을 실행하고 DataFrame을 반환합니다."""
return driver.execute_query(
cypher, parameters_=params, result_transformer_=Result.to_df
)
그래프 추출 시에 우리는 300의 청크 크기를 사용했습니다. 이후 저자들은 기본 청크 크기를 1200으로 변경했습니다. 다음 Cypher 문을 사용하여 청크 크기를 확인할 수 있습니다.
db_query(
"MATCH (n:__Chunk__) RETURN n.n_tokens as token_count, count(*) AS count"
)
# token_count count
# 300 230
# 155 1
230개의 청크에는 300개의 토큰이 있고, 마지막 청크에는 155개의 토큰만 있어요. 이제 예시 엔티티와 설명을 확인해볼게요.
db_query(
"MATCH (n:__Entity__) RETURN n.name AS name, n.description AS description LIMIT 1"
)
결과

프로젝트 Gutenberg에 대한 설명이 어딘가 책에 나와 있을 것 같아요, 아마도 처음에요. 우리는 MSFT GraphRAG 논문에서 소개된 entity 이름보다 더 세밀하고 복잡한 정보를 포함할 수 있는 설명이 어떻게 더 많은 정보를 전달하는지 볼 수 있어요.
예시 관계도 확인해 볼까요?
db_query(
"MATCH ()-[n:RELATED]->() RETURN n.description AS description LIMIT 5"
)
결과

MSFT GraphRAG는 단순히 엔티티간의 간단한 관계 유형을 추출하는 것을 넘어서 세부적인 관계 설명을 캡처함으로써 더 다채로운 정보를 캡처할 수 있습니다. 이 능력을 통해 간단한 관계 유형보다 섬세한 정보를 캡처할 수 있습니다.
또한 단일 커뮤니티와 해당 생성된 설명을 살펴볼 수도 있습니다.
db_query("""
MATCH (n:__Community__)
RETURN n.title AS title, n.summary AS summary, n.full_content AS full_content LIMIT 1
""")
결과

커뮤니티는 LLM을 사용하여 제목, 요약 및 전체 내용을 생성합니다. 작성자가 검색 중인 동안 전체 컨텍스트를 사용하는지 또는 요약만 사용하는지 확인하지는 않았지만, 둘 중 하나를 선택할 수 있습니다. 전체 내용에서 정보가 나온 엔티티와 관계를 가리키는 인용을 관찰할 수 있습니다. 가끔 LLM은 인용이 너무 길면 다음 예시와 같이 축소할 때가 있습니다.
[Data: Entities (11, 177); Relationships (25, 159, 20, 29, +more)]
- 더 보기 기호를 확장하는 방법이 없으므로 LLM이 긴 인용구를 처리하는 재미있는 방법입니다.
이제 일부 분포를 평가해 봅시다. 먼저 텍스트 청크에서 추출된 개체의 수 분포를 살펴보겠습니다.
entity_df = db_query(
"""
MATCH (d:__Chunk__)
RETURN count {(d)-[:HAS_ENTITY]->()} AS entity_count
"""
)
# 분포 플롯
plt.figure(figsize=(10, 6))
sns.histplot(entity_df['entity_count'], kde=True, bins=15, color='skyblue')
plt.axvline(entity_df['entity_count'].mean(), color='red', linestyle='dashed', linewidth=1)
plt.axvline(entity_df['entity_count'].median(), color='green', linestyle='dashed', linewidth=1)
plt.xlabel('Entity Count', fontsize=12)
plt.ylabel('Frequency', fontsize=12)
plt.title('Entity Count의 분포', fontsize=15)
plt.legend({'평균': entity_df['entity_count'].mean(), '중앙값': entity_df['entity_count'].median()})
plt.show()
결과
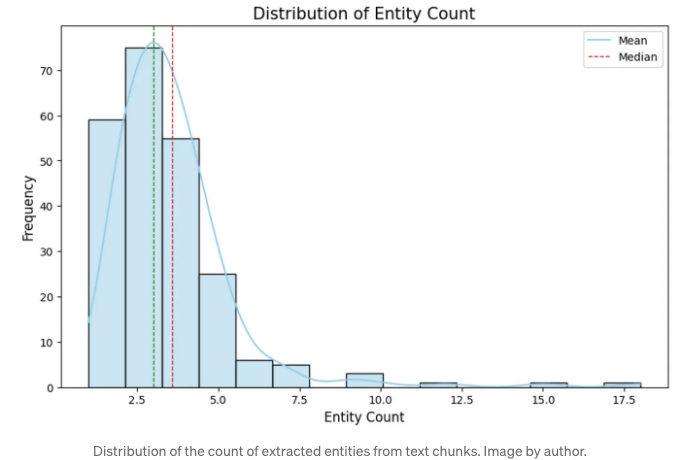
안녕하세요! 텍스트 청크는 토큰 300개로 구성되어 있습니다. 따라서 추출된 엔티티 수는 상대적으로 적으며, 텍스트 청크당 약 세 개의 엔티티가 있는 평균을 보여줍니다. 추출은 어떠한 추출 단계도 거치지 않고(단일 추출 실행) 수행되었습니다. 만약 gleanings 수를 늘린다면 분포를 살펴보는 것이 흥미로울 것입니다.
이제 노드 차수 분포를 평가할 것입니다. 노드 차수란 노드가 가지고 있는 관계의 수를 의미합니다.
degree_dist_df = db_query(
"""
MATCH (e:__Entity__)
RETURN count {(e)-[:RELATED]-()} AS node_degree
"""
)
# 평균과 중앙값 계산
mean_degree = np.mean(degree_dist_df['node_degree'])
percentiles = np.percentile(degree_dist_df['node_degree'], [25, 50, 75, 90])
# 로그 스케일로 히스토그램 생성
plt.figure(figsize=(12, 6))
sns.histplot(degree_dist_df['node_degree'], bins=50, kde=False, color='blue')
# x축에 로그 스케일 사용
plt.yscale('log')
# 레이블과 제목 추가
plt.xlabel('노드 차수')
plt.ylabel('개수 (로그 스케일)')
plt.title('노드 차수 분포')
# 평균, 중앙값, 백분위수 라인 추가
plt.axvline(mean_degree, color='red', linestyle='dashed', linewidth=1, label=f'평균: {mean_degree:.2f}')
plt.axvline(percentiles[0], color='purple', linestyle='dashed', linewidth=1, label=f'25번째 백분위수: {percentiles[0]:.2f}')
plt.axvline(percentiles[1], color='orange', linestyle='dashed', linewidth=1, label=f'50번째 백분위수: {percentiles[1]:.2f}')
plt.axvline(percentiles[2], color='yellow', linestyle='dashed', linewidth=1, label=f'75번째 백분위수: {percentiles[2]:.2f}')
plt.axvline(percentiles[3], color='brown', linestyle='dashed', linewidth=1, label=f'90번째 백분위수: {percentiles[3]:.2f}')
# 범례 추가
plt.legend()
# 플롯 보이기
plt.show()
결과
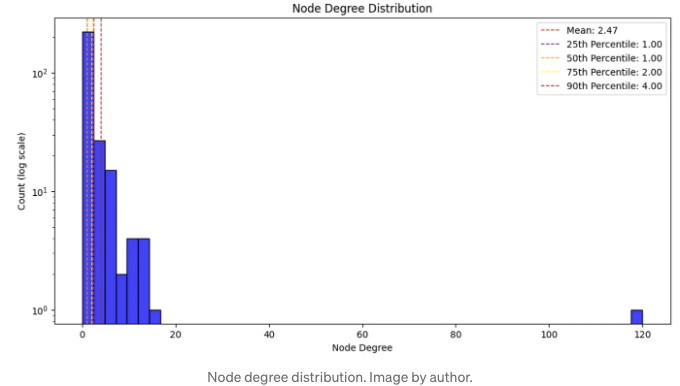
대부분의 실제 네트워크는 노드 차수 분포가 멱법칙을 따르며, 대부분의 노드는 상대적으로 작은 차수를 갖고 있고 일부 중요한 노드는 많은 차수를 갖습니다. 그래프가 작지만 노드 차수가 멱법칙을 따른다면 흥미로울 것입니다. 120개의 관계를 가진 엔티티를 식별하는 것이 흥미로울 것입니다 (엔티티의 43%와 연결됨).
db_query("""
MATCH (n:__Entity__)
RETURN n.name AS name, count{(n)-[:RELATED]-()} AS degree
ORDER BY degree DESC LIMIT 5""")
결과
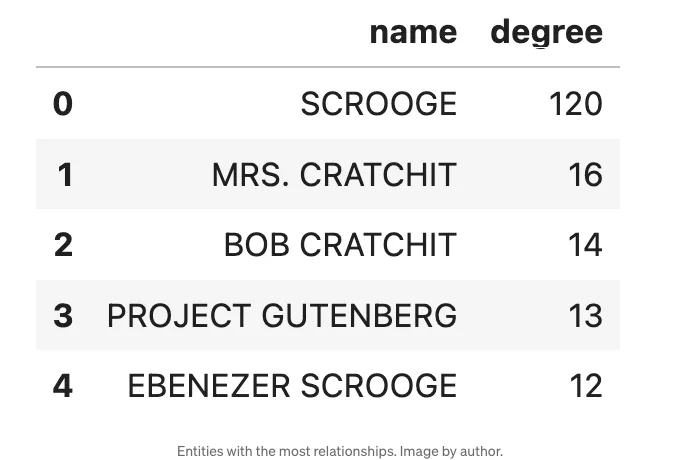
망설이지 마십시오. 우리는 스쿠루지가 책의 주요 캐릭터라고 가정할 수 있습니다. 또한 에베네저 스쿠루지와 스쿠루지가 사실상 동일한 개체임을 추측해 볼 수 있지만, MSFT GraphRAG에는 개체 해결 단계가 없기 때문에 합쳐지지 않았습니다.
이는 데이터의 분석 및 정리가 중요한 단계라는 것을 보여주며, Project Gutenberg은 책 이야기의 일부가 아님에도 불구하고 13개의 관계를 갖고 있다는 것을 보여줍니다.
마지막으로, 계층 수준별 커뮤니티 크기 분포를 살펴보겠습니다.
community_data = db_query("""
MATCH (n:__Community__)
RETURN n.level AS level, count{(n)-[:IN_COMMUNITY]-()} AS members
""")
stats = community_data.groupby('level').agg(
min_members=('members', 'min'),
max_members=('members', 'max'),
median_members=('members', 'median'),
avg_members=('members', 'mean'),
num_communities=('members', 'count'),
total_members=('members', 'sum')
).reset_index()
# 상자 그림 생성
plt.figure(figsize=(10, 6))
sns.boxplot(x='level', y='members', data=community_data, palette='viridis')
plt.xlabel('Level')
plt.ylabel('Members')
# 통계적 주석 추가
for i in range(stats.shape[0]):
level = stats['level'][i]
max_val = stats['max_members'][i]
text = (f"num: {stats['num_communities'][i]}\n"
f"all_members: {stats['total_members'][i]}\n"
f"min: {stats['min_members'][i]}\n"
f"max: {stats['max_members'][i]}\n"
f"med: {stats['median_members'][i]}\n"
f"avg: {stats['avg_members'][i]:.2f}")
plt.text(level, 85, text, horizontalalignment='center', fontsize=9)
plt.show()
결과
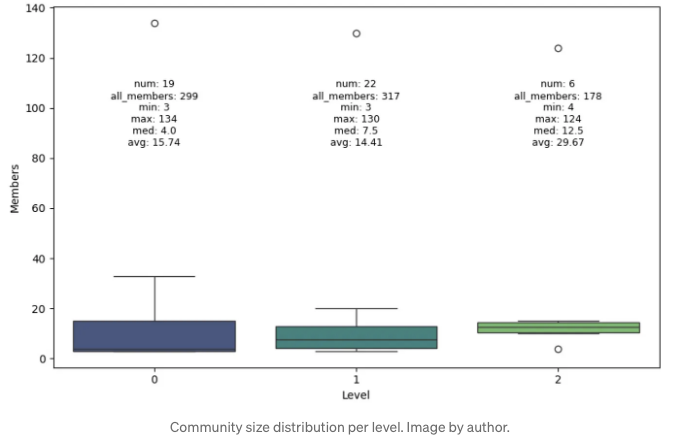
라이덴 알고리즘은 세 가지 수준의 커뮤니티를 식별했습니다. 더 높은 수준의 커뮤니티가 평균적으로 더 크다는 것이죠. 하지만, 모든 멤버 수를 확인해보면 각 수준마다 노드의 총 개수가 다르다는 점에 대해 제가 알지 못하는 기술적 세부사항이 있습니다. 이론상으로는 동일해야 하지만요. 또한, 왜 레벨이 오르면 커뮤니티가 합쳐진다면 레벨 0에 19개의 커뮤니티가 있고 레벨 1에는 22개의 커뮤니티가 있는 건가요? 저자들이 여기서 일부 최적화 및 트릭을 수행했는데, 제가 아직 자세히 탐구하지 못한 부분입니다.
검색기 구현하기
이 블로그 포스트의 마지막 부분에서는 MSFT 그래프 RAG에서 명시된 로컬 및 글로벌 검색기에 대해 논의할 것입니다. 검색기는 LangChain 및 LlamaIndex와 통합되어 구현될 예정입니다.
로컬 검색기
로컬 검색기는 관련 노드를 식별하기 위해 벡터 검색을 사용하고, 연결된 정보를 수집하여 LLM 프롬프트에 삽입합니다.
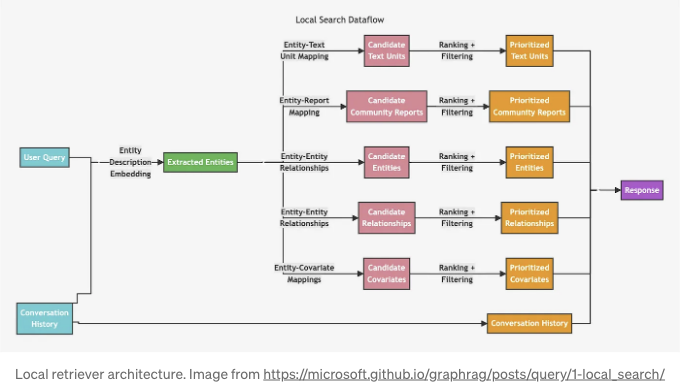
이 다이어그램은 복잡해 보일 수 있지만 쉽게 구현할 수 있습니다. 엔티티 설명의 텍스트 임베딩을 기반으로 벡터 유사성 검색을 사용하여 관련 엔티티를 식별합니다. 관련 엔티티가 식별되면 관련 텍스트 청크, 관계, 커뮤니티 요약 등으로 이동할 수 있습니다. 벡터 유사성 검색을 사용한 뒤 그래프 전체를 순회하는 패턴은 LangChain 및 LlamaIndex의 retrieval_query 기능을 사용하여 쉽게 구현할 수 있습니다.
먼저 벡터 인덱스를 구성해야 합니다.
index_name = "entity"
db_query(
"""
CREATE VECTOR INDEX """
+ index_name
+ """ IF NOT EXISTS FOR (e:__Entity__) ON e.description_embedding
OPTIONS {indexConfig: {
`vector.dimensions`: 1536,
`vector.similarity_function`: 'cosine'
}
"""
)
또한, 커뮤니티 가중치를 계산하고 저장할 것입니다. 커뮤니티 가중치는 커뮤니티에 속한 엔티티가 나타나는 고유한 텍스트 청크의 수로 정의됩니다.
db_query(
"""
MATCH (n:`__Community__`)<-[:IN_COMMUNITY]-()<-[:HAS_ENTITY]-(c)
WITH n, count(distinct c) AS chunkCount
SET n.weight = chunkCount"""
)
각 섹션에서 후보자 (텍스트 단위, 커뮤니티 보고서 등)의 수는 구성 가능합니다. 원래 구현은 토큰 수에 기반한 복잡한 필터링이 약간 있지만, 여기서는 간단하게 만들겠습니다. 기본 구성 값을 기반으로 한 다음 간단한 상위 후보자 필터 값들을 개발했습니다.
topChunks = 3
topCommunities = 3
topOutsideRels = 10
topInsideRels = 10
topEntities = 10
우리는 LangChain 구현부터 시작할 거예요. 정의할 필요가 있는 유일한 것은 retrieval_query인데, 이 부분이 조금 복잡합니다.
lc_retrieval_query = """
WITH collect(node) as nodes
// Entity - Text Unit Mapping
WITH
collect {
UNWIND nodes as n
MATCH (n)<-[:HAS_ENTITY]->(c:__Chunk__)
WITH c, count(distinct n) as freq
RETURN c.text AS chunkText
ORDER BY freq DESC
LIMIT $topChunks
} AS text_mapping,
// Entity - Report Mapping
collect {
UNWIND nodes as n
MATCH (n)-[:IN_COMMUNITY]->(c:__Community__)
WITH c, c.rank as rank, c.weight AS weight
RETURN c.summary
ORDER BY rank, weight DESC
LIMIT $topCommunities
} AS report_mapping,
// Outside Relationships
collect {
UNWIND nodes as n
MATCH (n)-[r:RELATED]-(m)
WHERE NOT m IN nodes
RETURN r.description AS descriptionText
ORDER BY r.rank, r.weight DESC
LIMIT $topOutsideRels
} as outsideRels,
// Inside Relationships
collect {
UNWIND nodes as n
MATCH (n)-[r:RELATED]-(m)
WHERE m IN nodes
RETURN r.description AS descriptionText
ORDER BY r.rank, r.weight DESC
LIMIT $topInsideRels
} as insideRels,
// Entities description
collect {
UNWIND nodes as n
RETURN n.description AS descriptionText
} as entities
// We don't have covariates or claims here
RETURN {Chunks: text_mapping, Reports: report_mapping,
Relationships: outsideRels + insideRels,
Entities: entities} AS text, 1.0 AS score, {} AS metadata
"""
lc_vector = Neo4jVector.from_existing_index(
OpenAIEmbeddings(model="text-embedding-3-small"),
url=NEO4J_URI,
username=NEO4J_USERNAME,
password=NEO4J_PASSWORD,
index_name=index_name,
retrieval_query=lc_retrieval_query
)
이 Cypher 쿼리는 일련의 노드에 대해 여러 분석 작업을 수행하여 관련된 텍스트 데이터를 추출하고 조직화합니다:
-
Entity-Text Unit Mapping: 각 노드에 대해 쿼리는 연결된 텍스트 청크('
__Chunk__')를 식별하고, 각 청크에 연결된 노드 수를 집계한 후 빈도 순으로 정렬합니다. 상위 청크는text_mapping으로 반환됩니다. -
Entity-Report Mapping: 각 노드에 대해 쿼리는 관련된 커뮤니티('
__Community__')를 찾아 순위와 가중치에 기반한 상위 커뮤니티의 요약을 반환합니다. -
외부 관계: 이 섹션은 관련 엔티티('m')가 초기 노드 집합의 일부가 아닌 관계('RELATED') 설명을 추출합니다. 관계는 순위가 매겨지고 최상위 외부 관계로 제한됩니다.
-
내부 관계: 외부 관계와 유사하지만, 이번에는 초기 노드 집합 내에서 두 엔티티가 모두 속한 관계만을 고려합니다.
- Entities Description: 각 노드의 설명을 단순히 수집합니다.
마지막으로, 이 쿼리는 수집된 데이터를 청크, 보고서, 내부 및 외부 관계, 엔터티 설명으로 구성된 구조화된 결과로 결합시킵니다. 그리고 기본 점수와 빈 메타데이터 객체도 함께 포함됩니다. 결과에 어떤 영향을 미치는지 테스트하기 위해 일부 검색 부분을 제거할 수 있는 옵션이 있습니다.
이제 아래의 코드를 사용하여 리트리버를 실행할 수 있습니다:
docs = lc_vector.similarity_search(
"Cratchitt 가족에 대해 알고 있는 내용은 무엇인가요?",
k=topEntities,
params={
"topChunks": topChunks,
"topCommunities": topCommunities,
"topOutsideRels": topOutsideRels,
"topInsideRels": topInsideRels,
},
)
# print(docs[0].page_content)
동일한 검색 패턴은 LlamaIndex로 구현할 수 있습니다. LlamaIndex에서는 먼저 벡터 인덱스가 작동하도록 노드에 메타데이터를 추가해야 합니다. 해당 노드에 기본 메타데이터가 추가되지 않으면 벡터 인덱스에서 오류가 발생할 수 있습니다.
# https://github.com/run-llama/llama_index/blob/main/llama-index-core/llama_index/core/vector_stores/utils.py#L32
from llama_index.core.schema import TextNode
from llama_index.core.vector_stores.utils import node_to_metadata_dict
content = node_to_metadata_dict(TextNode(), remove_text=True, flat_metadata=False)
db_query(
"""
MATCH (e:__Entity__)
SET e += $content""",
{"content": content},
)
다시 한번, LlamaIndex에서 retrieval_query 기능을 사용하여 검색기를 정의할 수 있습니다. LangChain과 달리 최상위 후보 필터 매개변수를 전달하는 데 쿼리 매개변수 대신 f-string을 사용할 것입니다.
retrieval_query = f"""
WITH collect(node) as nodes
// Entity - Text Unit Mapping
WITH
nodes,
collect {
UNWIND nodes as n
MATCH (n)<-[:HAS_ENTITY]->(c:__Chunk__)
WITH c, count(distinct n) as freq
RETURN c.text AS chunkText
ORDER BY freq DESC
LIMIT {topChunks}
} AS text_mapping,
// Entity - Report Mapping
collect {
UNWIND nodes as n
MATCH (n)-[:IN_COMMUNITY]->(c:__Community__)
WITH c, c.rank as rank, c.weight AS weight
RETURN c.summary
ORDER BY rank, weight DESC
LIMIT {topCommunities}
} AS report_mapping,
// Outside Relationships
collect {
UNWIND nodes as n
MATCH (n)-[r:RELATED]-(m)
WHERE NOT m IN nodes
RETURN r.description AS descriptionText
ORDER BY r.rank, r.weight DESC
LIMIT {topOutsideRels}
} as outsideRels,
// Inside Relationships
collect {
UNWIND nodes as n
MATCH (n)-[r:RELATED]-(m)
WHERE m IN nodes
RETURN r.description AS descriptionText
ORDER BY r.rank, r.weight DESC
LIMIT {topInsideRels}
} as insideRels,
// Entities description
collect {
UNWIND nodes as n
RETURN n.description AS descriptionText
} as entities
// 우리는 여기서 공변량이나 주장을 가지고 있지 않습니다.
RETURN "Chunks:" + apoc.text.join(text_mapping, '|') + "\nReports: " + apoc.text.join(report_mapping,'|') +
"\nRelationships: " + apoc.text.join(outsideRels + insideRels, '|') +
"\nEntities: " + apoc.text.join(entities, "|") AS text, 1.0 AS score, nodes[0].id AS id, {_node_type:nodes[0]._node_type, _node_content:nodes[0]._node_content} AS metadata
"""
또한 반환 값이 약간 다릅니다. 메타데이터로 노드 유형과 내용을 반환해야 합니다. 그렇지 않으면 리트리버가 제대로 동작하지 않을 수 있습니다. 이제 우리는 Neo4j 벡터 저장소를 인스턴스화하고 쿼리 엔진으로 사용합니다.
neo4j_vector = Neo4jVectorStore(
NEO4J_USERNAME,
NEO4J_PASSWORD,
NEO4J_URI,
embed_dim,
index_name=index_name,
retrieval_query=retrieval_query,
)
loaded_index = VectorStoreIndex.from_vector_store(neo4j_vector).as_query_engine(
similarity_top_k=topEntities, embed_model=OpenAIEmbedding(model="text-embedding-3-large")
)
이제 GraphRAG 로컬 리트리버를 테스트할 수 있습니다.
response = loaded_index.query("What do you know about Scrooge?")
print(response.response)
#print(response.source_nodes[0].text)
# Scrooge is an employee who is impacted by the generosity and festive spirit
# of the Fezziwig family, particularly Mr. and Mrs. Fezziwig. He is involved
# in the memorable Domestic Ball hosted by the Fezziwigs, which significantly
# influences his life and contributes to the broader narrative of kindness
# and community spirit.
한 가지 떠오르는 점은 벡터 검색만 사용하는 것이 아닌 관련 엔티티를 찾기 위해 하이브리드 접근법(벡터 + 키워드)을 사용하여 로컬 검색을 개선할 수 있다는 것입니다.
글로벌 검색기
글로벌 검색기 아키텍처는 조금 더 직관적입니다. 지정된 계층 수준의 모든 커뮤니티 요약본을 반복하고 중간 요약본을 생성한 다음 중간 요약본을 기반으로 최종 응답을 생성하는 것으로 보입니다.
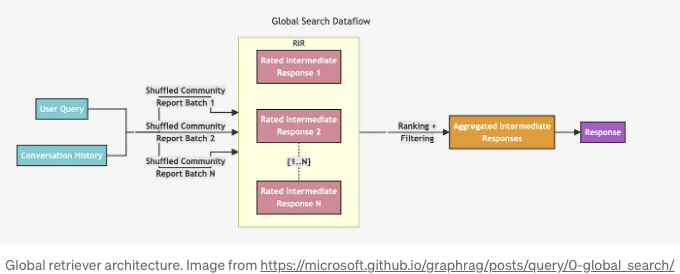
미리 정의할 계층 수준을 결정해야 합니다. 어떤 것이 더 잘 작동할지 알 수 없어서 간단한 결정이 아닙니다. 계층 수준이 높을수록 커뮤니티는 커지지만 수가 적습니다. 이 정보가 수동으로 요약을 검토하지 않아도 가지고 있는 유일한 정보입니다.
다른 매개변수들은 순위나 가중치 임계값 아래에 있는 커뮤니티를 무시할 수 있게 해줍니다. 여기서는 사용하지 않겠습니다. LangChain을 사용하여 글로벌 검색기를 구현할 것이며, GraphRAG 논문에 있는 맵 및 리듀스 프롬프트를 사용할 것입니다. 시스템 프롬프트가 매우 길기 때문에 여기에 포함하지 않을 것이며 체인 구성도 역시 포함하지 않을 것입니다. 그러나 모든 코드는 노트북에 사용 가능합니다.
def global_retriever(query: str, level: int, response_type: str = response_type) -> str:
community_data = graph.query(
"""
MATCH (c:__Community__)
WHERE c.level = $level
RETURN c.full_content AS output
""",
params={"level": level},
)
intermediate_results = []
for community in tqdm(community_data, desc="Processing communities"):
intermediate_response = map_chain.invoke(
{"question": query, "context_data": community["output"]}
)
intermediate_results.append(intermediate_response)
final_response = reduce_chain.invoke(
{
"report_data": intermediate_results,
"question": query,
"response_type": response_type,
}
)
return final_response
이제 테스트해 보겠습니다.
print(global_retriever("이야기의 요지는 무엇입니까?", 2))
결과
응답은 모든 커뮤니티를 순회하는 글로벌 검색기에 적합한만큼 꽤 길고 철저합니다. 커뮤니티 계층 수준을 변경하면 응답이 어떻게 변하는 지 테스트할 수 있습니다.
요약
이 블로그 포스트에서는 Microsoft의 GraphRAG를 Neo4j에 통합하고 LangChain 및 LlamaIndex를 사용하여 리트리버를 구현하는 방법을 보여드렸습니다. 이를 통해 GraphRAG를 다른 리트리버나 에이전트와 원활하게 통합할 수 있습니다. 로컬 리트리버는 벡터 유사성 검색과 그래프 탐색을 결합하고, 글로벌 리트리버는 커뮤니티 요약본을 반복하여 포괄적인 응답을 생성합니다. 이 구현은 구조화된 지식 그래프와 언어 모델을 결합하여 정보 검색 및 질문 응답을 향상시키는 능력을 보여줍니다. 이러한 지식 그래프를 사용하여 사용자 정의 및 실험의 여지가 있다는 점을 강조하고, 다음 블로그 포스트에서 더 자세히 다루겠습니다.
언제나 코드는 GitHub에서 사용할 수 있습니다.