검색 증강 생성 (RAG)은 질문 응답, 정보 검색 및 대화형 AI와 같은 자연어 처리 작업의 성능을 향상시킬 수 있는 강력한 방법입니다. 관련 외부 정보를 활용하여 더 정확하고 맥락에 적합한 응답을 생성함으로써 이를 달성합니다. 기존 RAG 기술은 종종 텍스트의 여러 측면을 포착하지 못하는데 그 이유는 최종 레이어의 임베딩에만 의존하기 때문입니다. 이 한계를 해결하기 위해, 이 논문은 Multi-Head RAG (MRAG)를 소개합니다. MRAG는 Transformer 모델의 멀티헤드 어텐션 레이어에서 디코더 레이어가 아닌 활성화를 사용하여 다양한 측면의 문서를 검색하는 혁신적인 접근 방식입니다.
MRAG는 Transformer 모델의 멀티헤드 어텐션 메커니즘을 활용하여 검색 프로세스를 향상시킵니다. Transformer 내의 다른 어텐션 헤드는 데이터의 여러 측면에 집중하는 방법을 학습하여 서로 다른 특징이나 속성을 포착합니다. 이러한 어텐션 헤드에서 활성화를 사용하여 MRAG는 데이터 항목 및 쿼리의 여러 측면을 대표하는 임베딩을 생성합니다. 이 방법은 데이터의 다양한 정보가 필요한 쿼리의 검색 정확도를 향상시켜, 데이터의 다른 차원을 효과적으로 표현하고 액세스합니다. 표준 RAG에서는 단순히 마지막 피드포워드 디코더 레이어만을 활용하는 반면, MRAG에서는 어텐션 헤드를 포함한 마지막 h개의 레이어가 고려됩니다.
주요 요점:
• Multi-Head Attention 활용: MRAG는 다양한 데이터 측면을 캡처하기 위해 다중 헤드 어텐션 레이어의 활성화를 키로 사용합니다.
• 검색 정확도 향상: 쿼리와 데이터의 다양한 측면을 포괄하는 임베딩을 생성함으로써, MRAG는 복잡한 다층 쿼리의 검색을 향상시킵니다.
• 원활한 통합: MRAG는 기존 RAG 프레임워크 및 벤치마킹 도구와 통합할 수 있어 다양한 데이터 저장소와 응용 프로그램에 적응할 수 있습니다.
• 평가와 효과성: 이 접근 방식은 합성 데이터셋 및 실제 사용 사례에 대한 평가를 통해 표준 RAG 기준선 대비 최대 20%의 관련성 향상을 시연했습니다.
MRAG Formulation and Pipeline:
- 데이터 준비: 원래 논문에서 설명한 방법론과 비교해서 데이터 준비 과정에 약간의 수정이 있습니다. 지정된 청크 크기로 재귀적 텍스트 분할기를 사용하여 문서를 전처리한 후, 텍스트 세그먼트가 생성됩니다. 이러한 세그먼트는 임베딩 모델을 통해 처리되어 마지막 h 개의 레이어에서 단일 측면 임베딩이 생성됩니다. 이 임봄할 때에는 BAAI/bge-large-en-v1.5 임베딩 모델이 사용되었습니다. 이러한 임베딩을 벡터 데이터베이스에 저장할 때, 모든 h 개의 임베딩 공간에 코사인 거리를 사용하여 중요도 점수를 할당합니다.
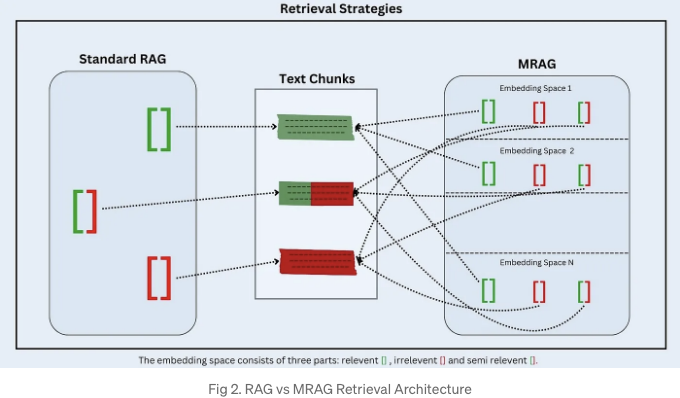
- 쿼리 실행: 쿼리 실행 중에는 데이터 준비 단계에서 사용된 모델과 동일한 모델을 사용하여 쿼리의 다중 측면 임베딩을 생성합니다. 그런 다음 쿼리 임베딩을 기반으로 데이터베이스에서 가장 가까운 임베딩 및 해당 텍스트 청크를 검색하는데, 임베딩 공간에 대한 모든 임베딩 공간에 대해 전통적인 검색-증강 생성 (RAG) 전략을 사용합니다. 상위 k 청크를 얻기 위해 특수화된 검색 전략을 적용합니다. 예를 들어, 투표 메커니즘이나 임베딩 공간과 관련된 중요도 점수의 L2 노름을 계산하는 방법 등이 있습니다.
# 중요도 점수 계산하기
def calculate_importance_scores(embeddings):
importance_scores = []
for head in embeddings:
a_i = 0
b_i = 0
count_a_i = 0
count_b_i = 0
# a_i 계산
for e_ij in head:
a_i += np.linalg.norm(e_ij)
count_a_i += 1
# b_i 계산
for e_ih in head:
b_i += cosine(e_ij, e_ih)
count_b_i += 1
# 평균 계산
if count_a_i > 0:
a_i /= count_a_i
if count_b_i > 0:
b_i /= count_b_i
# 헤드에 대한 중요도 점수 계산
s_i = a_i * b_i
importance_scores.append(s_i)
return importance_scores
벡터 관리 데이터베이스:
PostgreSQL 데이터베이스가 벡터 데이터베이스로 사용되었습니다. 새로운 기사가 추가되면 해당 텍스트 레이블이 articles 테이블에 저장되어 기사의 임베딩을 참조하는 데 사용할 수 있는 article_id가 생성됩니다. 기사의 표준 임베딩은 표준 테이블에 단일 벡터로 저장되며, 레이어 간에 멀티 측면 정보를 포착하는 주의 기반 임베딩은 attention 테이블에 저장됩니다.
표준 임베딩의 분할 버전은 cut_standard 테이블에 저장되어 자세한 유사성 검색을 가능하게 합니다. 데이터베이스는 또한 이러한 임베딩에 대한 척도를 유지합니다: attention 임베딩의 attention_scales 및 분할된 임베딩의 cut_standard_scales. 평균 노름 및 쌍별 코사인 거리에서 계산된 이러한 척도는 임베딩의 다른 측면에 중요도를 할당하여 유사성 검색을 최적화하는 데 도움이 됩니다.
결론 :
검색 증강 생성 (RAG)은 대형 언어 모델 (LLMs)을 개선하지만 다양한 쿼리에 대해 분산된 임베딩으로 전통적인 방법들이 어려워합니다. 멀티 헤드 RAG (MRAG)는 디코더 모델로부터 멀티 헤드 어텐션을 활용하여 다양한 데이터 측면을 포착하여 더 정확한 임베딩을 만듭니다. MRAG는 기존 방법과 비교해서 검색 정확도를 최대 20% 향상시키고 있으며 비용 효율적이고 에너지를 효과적으로 활용하여 현재 시스템에 매끄럽게 통합됩니다.
코드 : GitHub 링크
참고문헌:
- Multi-Head RAG: Solving Multi-Aspect Problems with LLMs by Maciej Besta, Ales Kubicek, Roman Niggli, Robert Gerstenberger, Lucas Weitzendorf, Mingyuan Chi, Patrick Iff, Joanna Gajda, Piotr Nyczyk, Jürgen Müller, Hubert Niewiadomski, Marcin Chrapek, Michał Podstawski, Torsten Hoefler. 링크
- Hugging Face Massive Text Embedding Benchmark (MTEB) 리더보드.
- PostgreSQL 공식 문서
- MRAG 레포지토리