AI Horizon Forecast는 복잡한 AI 주제를 명확하게 설명해 주는 블로그입니다.
"생성 모델 AI 혁명"의 핵심은 2017년에 Google에 의해 소개된 Transformer 모델입니다.
그러나 모든 기술 혁명은 혼란을 초래합니다. 급격한 성장 환경에서 혁신을 중립적으로 평가하는 것은 어렵습니다. 그들의 영향을 측정하는 것은 더욱 어려운 일입니다.
이 AI 발전의 시작을 약속한 트랜스포머가 "논란 모델"이 되었습니다. 두 가지 극단적인 견해가 있습니다:
- 열렬한 채택자: NLP 외적으로 어디서든 트랜스포머를 사용합니다. 자신이 원치 않거나 할 수 없더라도 강제로 사용합니다 — 사내의 임원, 관리자, 투자자 등의 요구 때문입니다.
- 의심가와 루딧: 트랜스포머를 비롯한 AI 모델에 대해 비판합니다. 더 많은 데이터와 레이어를 가진 모델의 확장이 엄격한 증명에 기초한 우아한 수학적 모델을 능가할 수 있는 경우를 이해하거나 수용할 수 없습니다.
이제 먼지가 적정해지고 있으니, 무참한 연구할 시간입니다.
본문은 예측을 위한 트랜스포머에 초점을 맞추고 있습니다. 학계, 산업 및 선도적인 연구진들의 최신 개발에 대해 논의할 것입니다.
제가 테이블 태그를 마크다운 형식으로 변경하도록 하겠습니다.
예측 분야에서 딥러닝의 간단한 역사
2012년, AlexNet 모델은 컴퓨터 비전을 혁신하고 딥러닝의 뜰 떴다. 어떤 사람들은 그 해가 딥러닝이 탄생한 시기였다고 말할 수도 있습니다 (또는 신경망이 브랜드가 바뀐 시기).
처음에는 딥러닝이 자연어 처리(NLP)와 컴퓨터 비전에 주로 초점을 맞추었으며, 시계열 예측과 같은 분야는 탐험하지 않았습니다.
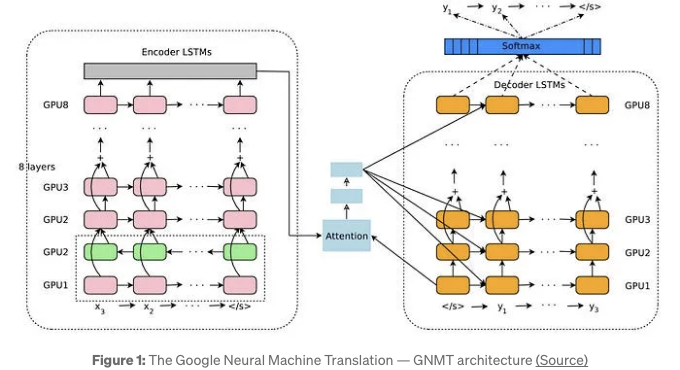
NLP에서 두 가지 주요 모델은 Word2Vec 및 어텐션을 사용한 LSTM이었습니다. 예를 들어 LSTM은 구글의 신경 기계 번역을 이끌었고(Figure 1), 그 당시 구글 번역의 근간이 되었습니다.
동시에, 연구자들과 기업들은 LSTM을 시계열 예측에 적용하기 시작했습니다. 결국 텍스트 번역은 일련의 일련의 작업이며 – 시계열 예측도 그렇습니다 (다단계 예측 시나리오에서).
하지만 그렇게 간단한 문제는 아닙니다. LSTMs가 NLP 및 기계 번역 작업에서 중대한 성과를 거뒀던 반면, 시계열 예측에서는 거의 혁명이 일어나지 않았습니다. LSTMs에는 통계 방법보다 일부 장점이 있습니다 (수도코드를 정지 형태로 만들어야 하는 추가 전 처리가 필요하지 않으며, 추가 미래 공변량을 허용한다 등).
LSTMs가 더 나은 과제 및 데이터 세트가 있는 것은 사실이지만, 주요 패러다임 변화의 증거는 없었습니다.
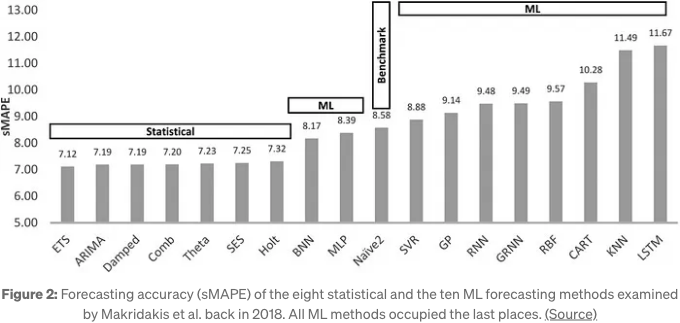
이것은 실제로 명백합니다. Makridakis 등이 2018년에 발표한 논문에서는 다양한 시계열 모델이 벤치마킹되었습니다. LSTMs를 포함한 ML 및 DL 모델은 성능이 나쁘게 나왔는데, 특히 LSTMs는 최악으로 순위했습니다! (그림 2)
결국 M4로 알려진 대회의 네 번째 반복에서 승리한 솔루션은 Uber 연구원이 개발한 LSTM 및 지수 평활 모델인 ES-RNN이었습니다.
문제는 명백했습니다: 연구원들이 적절한 적응 없이 딥러닝 방법을 시계열 예측에 부여하려고 했습니다.
하지만 시계열 예측은 난해한 작업이에요. 무작정 레이어나 뉴런을 더 추가한다고 해서 업적을 이루지는 않아요. 잘 알려지지 않았지만 효과적인 모델인 Temporal Convolutional Network (TCN)이 있어요. 이 모델은 Deepmind의 Wavenet에 바탕을 둔 숨은 보물이에요. 시계열 예측을 위해 CNN을 적용했어요 (도표 3):
![]()
시계열 예측을 혁신하려면 딥러닝이 독특한 접근 방식이 필요했어요. 이에 대해 다음에 알아볼게요.
딥러닝 예측 - 첫 번째 발견 (2017-2019)
이전에 Word2Vec를 언급한 적이 기억나시나요? 이 소설적인 방법은 임베딩 생성 개념을 소개했는데, 이를 통해 DL 모델이 한정된 어휘에서 단어를 입력으로 사용할 수 있게 되었습니다.
하지만 Word2Vec은 "앗, 이제 우리는 신경망에서 범주형 변수를 사용할 수 있게 되었네요"라는 뜻이기도 했어요.
임베딩을 사용하면 여러 시계열을 동시에 모델링할 수 있었는데, 다른 말로 하면 상호 학습을 통해 이점을 취하는 전역 모델을 구축할 수 있었습니다.
하지만 연구자들은 빠르게 깨달았어요. 성능을 향상시키는 데에는 임베딩이나 더 깊은 모델이 아니라, 통계 개념과 더 많은 데이터를 활용하는 우아한 아키텍처이었다는 것을요.
이 시대에서 성공을 거둔 두 가지 모델은 아마존 리서치의 DeepAR와 프로필 AI(요슈아 Bengio가 공동 창업한 스타트업)의 NBEATS입니다. 이후 구글이 강력한 모델인 Temporal Fusion Transformer (TFT)를 출시했으며, 이는 오늘날에도 SOTA로 남아 있습니다. TFT는 Nixtla의 메가 벤치마크에서 최고 성능을 자랑하는 모델 중 하나입니다. (2부에서 더 자세히 다룰 예정입니다).
첫 번째 주요 진전은 M4 대회 우승자보다 뛰어난 N-BEATS 모델이었습니다.
N-BEATS는 주요 모델로서 이유가 있습니다:
- Deep Learning + Signal Processing 철학을 결합했습니다.
- 해석 가능합니다 (추세 및 계절성).
- Transfer-learning을 지원합니다.
N-BEATS 이전에는 이러한 능력을 모두 갖춘 딥러닝 예측 모델이 없었습니다. 한 마디로 말하자면:
마찬가지로 DeepAR은 확률적 예측을 딥러닝에 통합한 최초의 모델 중 하나였습니다.
DeepAR은 여러 시계열에 대한 교차 학습을 활용하고 추가적인 공변량을 통합한 전역 모델로 작동했습니다. 모델 아키텍처는 다음과 같은 그림 5에 표시되어 있습니다:
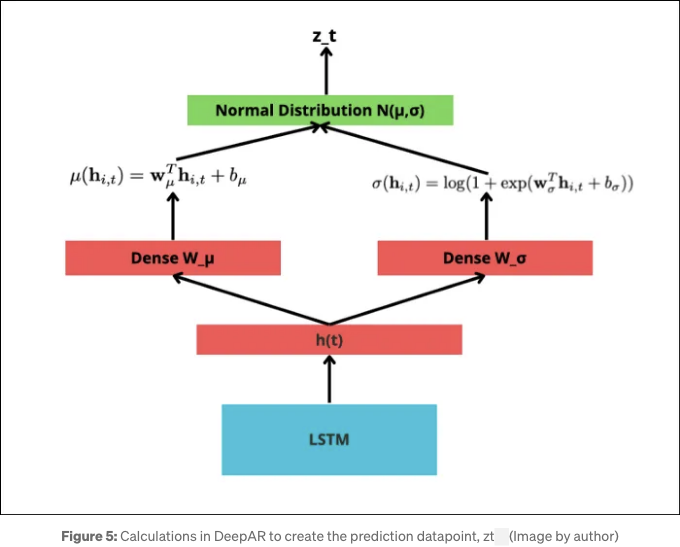
DeepAR는 본질적으로 LSTM을 사용하여 일반 분포의 매개변수를 예측하는 자기 회귀 모델입니다. 추론 중에는 이를 사용하여 표본을 추출하고 예측을 출력합니다.
이 성공은 DeepState(상태 공간 모델) 및 Deep GPVAR(가우시안 코푸라를 사용하는 모델)와 같은 변형을 영감으로 하였습니다.
하지만 딥 러닝이 시계열 예측에서 첫 걸음을 내디딘 동안, NLP는 Transformer의 출현으로 혁명을 경험하였습니다.
트랜스포머 소개
구글은 2017년에 "Attention is All You Need"이라는 논문에서 트랜스포머를 소개했어요. 이 논문에서 LSTM 기반의 번역 모델을 대체했죠.
트랜스포머는 우리가 이전에 언급한 두 모델의 자식이에요: Wavenet과 어텐션을 사용한 쌓인 LSTM.
- 어텐션을 사용한 LSTM은 더 긴 범위의 종속성을 학습할 수 있지만 병렬화가 어렵다고 해요.
- Wavenet은 컨볼루션을 사용하는데, 텍스트 데이터에는 적합하지 않지만 병렬화하기에 매우 좋아요.
따라서 Transformer는 두 세계의 혜택을 결합하기 위해 만들어졌어요.
Transformer는 멀티 헤드 어텐션을 활용한 인코더-디코더 모델이에요. 물론 어텐션(보다 간단한 형태에서)은 이미 [Bahdanau et al.]의 신경 기계 번역 작업에서 알려져 있었죠.
![]()
그리고 OpenAI는 GPT를 출시함으로써 Transformer 모델의 첫 인기 파생 버전을 선보였어요. GPT는 자연어 생성(NLG)에 적합한 디코더 전용 모델이에요.
몇 달 후에 Google은 시그니처 모델인 BERT를 출시했습니다. 이 모델은 인코더 전용 모델이었습니다. BERT는 자연어 이해 작업 (NLU)에 적합했습니다. 예를 들어 텍스트 분류와 명명된 엔티티 인식 등 (그림 6 참조). 따라서:
- 인코더 전용 모델은 양방향 어텐션을 사용하여 문장을 이해하고 문장 내의 가리고 있는 단어를 예측합니다. 이 모델들은 NLU 작업에 뛰어납니다.
- 디코더 전용 모델은 인과 어텐션을 사용하여 다음 단어를 예측하는 방식으로 작동합니다. 이 모델들은 NLG 작업에서 뛰어납니다.
당연하게도, 트랜스포머가 시리즈의 관심사로 떠올랐습니다. 가장 성공적인 모델 중 하나는 Temporal Fusion Transformer (TFT) 였습니다:
![]()
TFT는 혁신적인 모델로, 다음을 지원합니다:
- 다중 시계열: TFT는 수천 개의 단변량 또는 다변량 시계열에 대해 학습할 수 있습니다.
- Multi-Horizon Forecasting: 모델은 하나 이상의 대상 변수에 대한 여러 단계 예측을 출력합니다. 이는 quantile forecasts로서의 예측 간격을 포함합니다.
- 이질적인 특징: TFT는 시간 변화 및 정적 외생 변수를 포함한 다양한 유형의 특징을 지원합니다.
- 해석 가능한 예측: 예측은 변수 중요도 및 계절성 관점에서 해석될 수 있습니다.
TFT는 통계 모델 및 이전 ML 구현을 능가했습니다. 이는 다음과 같은 이유로 성공적이었습니다:
- 다중 헤드 어텐션을 그대로 복사하지 않았습니다. 대신, TFT는 어텐션을 해석 가능한 메커니즘으로 재구성했습니다.
- 어텐션은 장기적인 시간 동역학을 포착하는 데 사용되지만, TFT는 여전히 로컬 종속성을 모델링하기 위해 LSTM 인코더-디코더를 사용했습니다.
당신은 이제 패턴을 알아차리시나요?
그러나 딥 러닝과 트랜스포머는 자연어 처리에 비해 시계열 예측에서는 업데이트가 더 느리게 이루어졌어요.
심지어 컴퓨터 비전에서도, 첫 번째로 성공한 트랜스포머 응용 프로그램인 비전 트랜스포머(Vision Transformer, ViT)는 2020년에 발표되었어요. 이 모델은 추가적인 수정을 거쳐 많은 이미지 분류 작업에서 CNN을 능가하는 성과를 거뒀어요. 연구자들은 두 구성 요소를 결합하는 것이 더 나은 결과를 이끈 것을 발견했어요.
다행히 이 추세는 이제 바뀌었어요. 지난 몇 달 동안 우리는 생성적 AI 시계열 기반 모델들이 출시된 것을 보았어요.
이 놀라운 모델들은 훈련 없이 새 데이터에 대해 정확한 예측을 쉽게 출력할 수 있습니다. 이 모델들은 다음과 같습니다:
- TimeGPT (Nixtla)
- TimesFM (Google)
- MOIRAI (Salesforce)
- Tiny Time Mixers (IBM)
- MOMENT (Carnegie Mellon & Pennsylvania 대학)
최근에 Nixtla가 거대한 연구를 진행했는데(30k 시계열을 사용한 재현 가능한 벤치마크), 기초 모델이 평균적으로 다른 모델보다 우수한 성능을 보였다고 합니다.
![]()
결과가 놀라울 정도로 우수합니다. TimeGPT가 최고의 모델이며, 그 뒤를 이어 TimesFM이 나왔습니다. 이로써 TimesFM이 이 연구에서 최고의 오픈 소스 모델임을 확인할 수 있습니다!
마무리 맺음 - 다음 단계
이 기사를 주의 깊게 읽었다면, 딥 러닝의 발전이 시계열 예측에 어떤 영향을 미칠지 잘 이해하고 있을 것입니다.
그래도 개선할 부분이 있습니다.
딥 러닝이 시계열 예측에서 느리게 채택된 이유 중 하나는 도구 및 프레임워크의 부족이었습니다. PyTorch와 TensorFlow에서는 LSTMs 및 CNN과 같은 모델이 사용 가능했지만, 이러한 모델은 주로 다른 도메인에 사용되었습니다.
당시 Darts 및 Nixtla와 같은 라이브러리가 없었기 때문에 시계열 모델링을 위한 데이터를 준비, 정규화 및 슬라이스하는 것이 어려웠습니다. 추가 공변량 및 미래 알려진 변수를 처리하는 것은 작업을 더욱 어렵게 만들었습니다.
다음 주요 획기적인 발전은 아마도 다중 모달성일 것으로 예측됩니다. 시계열 모델이 시간 기반 데이터뿐만 아니라 텍스트와 같은 다른 유형의 데이터도 통합하는 모습을 상상해보세요! 기대해 봅시다!
읽어 주셔서 감사합니다!
- AI Horizon Forecast 뉴스레터를 구독해주세요!
참고 문헌
[1] Das et al., A decoder-only foundation model for time-series forecasting[2023]
[2] Woo et al., Unified Training of Universal Time Series Forecasting Transformers(February 2024)
[3] Ekambaram et al., Tiny Time Mixers (TTMs): Fast Pre-trained Models for Enhanced Zero/Few-Shot Forecasting of Multivariate Time Series (April 2024)
[4] Goswami et al., MOMENT: A Family of Open Time-Series Foundation Models(February 2024)